Hugging Face Transformers
9 minute read
Hugging Face Transformers 라이브러리를 사용하면 최첨단 NLP 모델(예: BERT)과 혼합 정밀도 및 그레이디언트 체크포인트와 같은 트레이닝 기술을 쉽게 사용할 수 있습니다. W&B 통합은 사용 편의성을 유지하면서도 대화형 중앙 집중식 대시보드에 풍부하고 유연한 실험 추적 및 모델 버전 관리를 추가합니다.
몇 줄의 코드로 차세대 로깅 구현
os.environ["WANDB_PROJECT"] = "<my-amazing-project>" # W&B 프로젝트 이름 지정
os.environ["WANDB_LOG_MODEL"] = "checkpoint" # 모든 모델 체크포인트 로깅
from transformers import TrainingArguments, Trainer
args = TrainingArguments(..., report_to="wandb") # W&B 로깅 켜기
trainer = Trainer(..., args=args)
시작하기: Experiments 추적
가입하고 API 키 만들기
API 키는 사용자의 컴퓨터가 W&B에 인증되도록 합니다. 사용자 프로필에서 API 키를 생성할 수 있습니다.
- 오른쪽 상단 모서리에 있는 사용자 프로필 아이콘을 클릭합니다.
- User Settings를 선택한 다음 API Keys 섹션으로 스크롤합니다.
- Reveal을 클릭합니다. 표시된 API 키를 복사합니다. API 키를 숨기려면 페이지를 새로 고칩니다.
wandb 라이브러리 설치 및 로그인
wandb 라이브러리를 로컬에 설치하고 로그인하는 방법:
-
WANDB_API_KEY환경 변수를 API 키로 설정합니다.export WANDB_API_KEY=<your_api_key> -
wandb라이브러리를 설치하고 로그인합니다.pip install wandb wandb login
pip install wandb
import wandb
wandb.login()
!pip install wandb
import wandb
wandb.login()
W&B를 처음 사용하는 경우 퀵스타트를 확인하는 것이 좋습니다.
프로젝트 이름 지정
W&B Project는 관련 Runs에서 기록된 모든 차트, 데이터 및 Models가 저장되는 곳입니다. 프로젝트 이름을 지정하면 작업을 구성하고 단일 프로젝트에 대한 모든 정보를 한 곳에 보관하는 데 도움이 됩니다.
Run을 프로젝트에 추가하려면 WANDB_PROJECT 환경 변수를 프로젝트 이름으로 설정하기만 하면 됩니다. WandbCallback은 이 프로젝트 이름 환경 변수를 가져와 Run을 설정할 때 사용합니다.
WANDB_PROJECT=amazon_sentiment_analysis
import os
os.environ["WANDB_PROJECT"]="amazon_sentiment_analysis"
%env WANDB_PROJECT=amazon_sentiment_analysis
Trainer를 초기화하기 전에 프로젝트 이름을 설정해야 합니다.프로젝트 이름이 지정되지 않은 경우 프로젝트 이름은 기본적으로 huggingface로 설정됩니다.
트레이닝 Runs를 W&B에 로깅
Trainer 트레이닝 인수를 정의할 때 코드 내부 또는 커맨드라인에서 가장 중요한 단계는 W&B를 사용하여 로깅을 활성화하기 위해 report_to를 "wandb"로 설정하는 것입니다.
TrainingArguments의 logging_steps 인수는 트레이닝 중에 트레이닝 메트릭이 W&B로 푸시되는 빈도를 제어합니다. run_name 인수를 사용하여 W&B에서 트레이닝 Run의 이름을 지정할 수도 있습니다.
이제 모델이 트레이닝하는 동안 손실, 평가 메트릭, 모델 토폴로지 및 그레이디언트를 W&B에 로깅합니다.
python run_glue.py \ # Python 스크립트 실행
--report_to wandb \ # W&B에 로깅 활성화
--run_name bert-base-high-lr \ # W&B Run 이름(선택 사항)
# 기타 커맨드라인 인수
from transformers import TrainingArguments, Trainer
args = TrainingArguments(
# 기타 인수 및 kwargs
report_to="wandb", # W&B에 로깅 활성화
run_name="bert-base-high-lr", # W&B Run 이름(선택 사항)
logging_steps=1, # W&B에 로깅 빈도
)
trainer = Trainer(
# 기타 인수 및 kwargs
args=args, # 트레이닝 인수
)
trainer.train() # 트레이닝을 시작하고 W&B에 로깅
Trainer를 TensorFlow TFTrainer로 바꾸기만 하세요.모델 체크포인트 설정
Artifacts를 사용하면 최대 100GB의 Models 및 Datasets를 무료로 저장한 다음 Weights & Biases Registry를 사용할 수 있습니다. Registry를 사용하면 Models를 등록하여 탐색하고 평가하고, 스테이징을 준비하거나 프로덕션 환경에 배포할 수 있습니다.
Hugging Face 모델 체크포인트를 Artifacts에 로깅하려면 WANDB_LOG_MODEL 환경 변수를 다음 _중 하나_로 설정합니다.
checkpoint:TrainingArguments에서args.save_steps마다 체크포인트를 업로드합니다.end:load_best_model_at_end도 설정된 경우 트레이닝이 끝나면 모델을 업로드합니다.false: 모델을 업로드하지 않습니다.
WANDB_LOG_MODEL="checkpoint"
import os
os.environ["WANDB_LOG_MODEL"] = "checkpoint"
%env WANDB_LOG_MODEL="checkpoint"
이제부터 초기화하는 모든 Transformers Trainer는 Models를 W&B Project에 업로드합니다. 로깅하는 모델 체크포인트는 Artifacts UI를 통해 볼 수 있으며 전체 모델 계보가 포함됩니다(UI에서 예제 모델 체크포인트를 보려면 여기 참조).
WANDB_LOG_MODEL이 end로 설정된 경우 모델은 model-{run_id}로 W&B Artifacts에 저장되고, WANDB_LOG_MODEL이 checkpoint로 설정된 경우 checkpoint-{run_id}로 저장됩니다.
그러나 TrainingArguments에서 run_name을 전달하면 모델은 model-{run_name} 또는 checkpoint-{run_name}로 저장됩니다.W&B Registry
체크포인트를 Artifacts에 로깅한 후에는 **Registry**를 사용하여 최고의 모델 체크포인트를 등록하고 팀 전체에서 중앙 집중화할 수 있습니다. Registry를 사용하면 작업별로 최고의 Models를 구성하고, Models의 라이프사이클을 관리하고, 전체 ML 라이프사이클을 추적 및 감사하고, 다운스트림 작업을 자동화할 수 있습니다.
모델 Artifact를 연결하려면 Registry를 참조하세요.
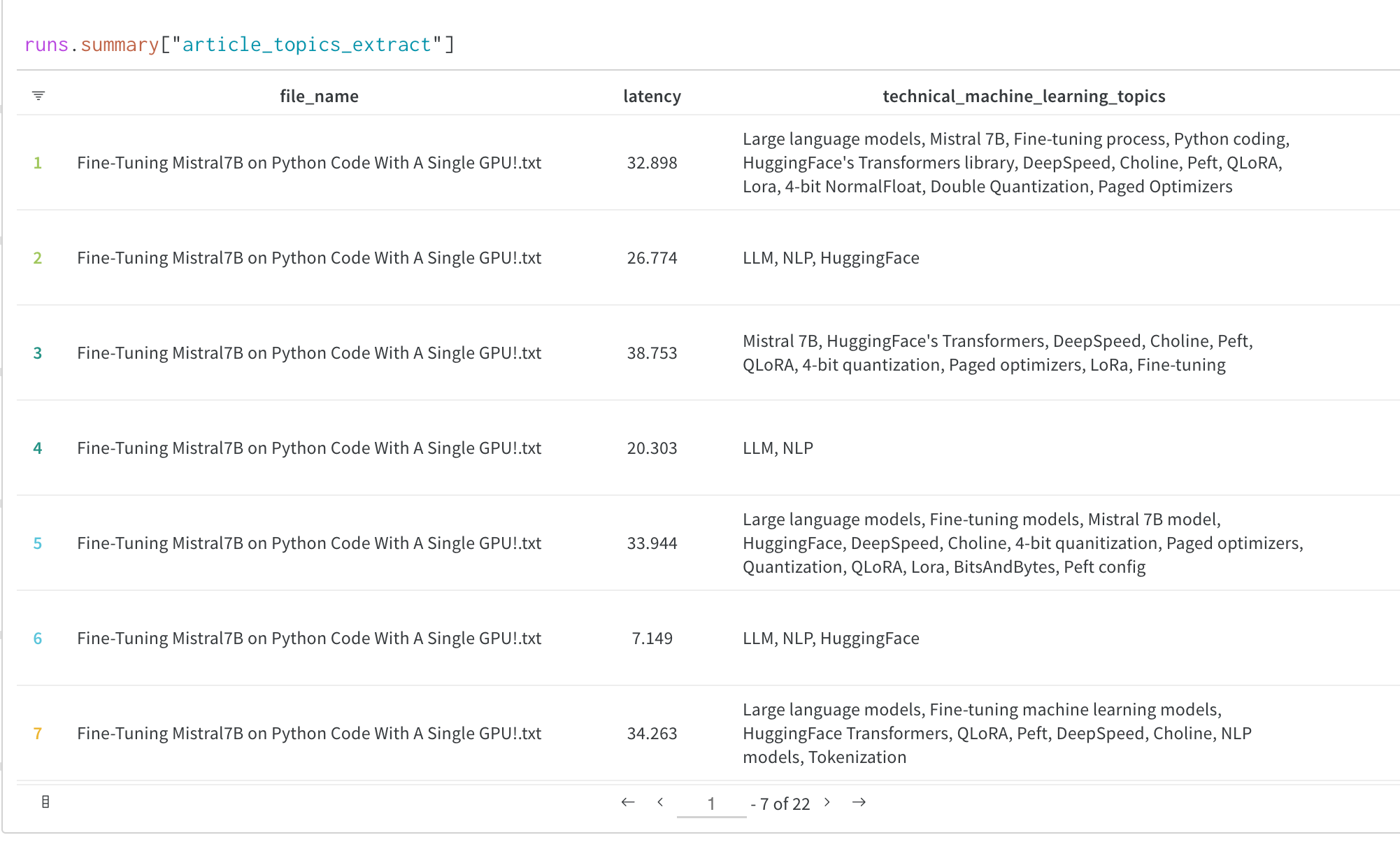
트레이닝 중 평가 결과 시각화
트레이닝 또는 평가 중 모델 출력을 시각화하는 것은 모델 트레이닝 방식을 실제로 이해하는 데 종종 필수적입니다.
Transformers Trainer의 콜백 시스템을 사용하면 모델의 텍스트 생성 출력 또는 기타 예측과 같은 추가적인 유용한 데이터를 W&B Tables에 로깅할 수 있습니다.
아래의 **사용자 지정 로깅 섹션**에서 트레이닝 중 평가 출력을 로깅하여 다음과 같은 W&B Table에 로깅하는 방법에 대한 전체 가이드를 참조하세요.
W&B Run 종료(노트북 전용)
트레이닝이 Python 스크립트에 캡슐화된 경우 스크립트가 완료되면 W&B Run이 종료됩니다.
Jupyter 또는 Google Colab 노트북을 사용하는 경우 wandb.finish()를 호출하여 트레이닝이 완료되었음을 알려야 합니다.
trainer.train() # 트레이닝을 시작하고 W&B에 로깅
# 트레이닝 후 분석, 테스트, 기타 로깅된 코드
wandb.finish()
결과 시각화
트레이닝 결과를 로깅했으면 W&B Dashboard에서 결과를 동적으로 탐색할 수 있습니다. 유연하고 대화형 시각화를 통해 한 번에 수십 개의 Runs를 비교하고, 흥미로운 발견을 확대하고, 복잡한 데이터에서 통찰력을 얻는 것이 쉽습니다.
고급 기능 및 FAQ
최고의 모델을 저장하는 방법은 무엇인가요?
TrainingArguments를 load_best_model_at_end=True로 Trainer에 전달하면 W&B는 가장 성능이 좋은 모델 체크포인트를 Artifacts에 저장합니다.
모델 체크포인트를 Artifacts로 저장하는 경우 Registry로 승격할 수 있습니다. Registry에서 다음을 수행할 수 있습니다.
- ML 작업별로 최고의 모델 버전을 구성합니다.
- Models를 중앙 집중화하고 팀과 공유합니다.
- 프로덕션을 위해 Models를 스테이징하거나 추가 평가를 위해 북마크합니다.
- 다운스트림 CI/CD 프로세스를 트리거합니다.
저장된 모델을 로드하는 방법은 무엇인가요?
WANDB_LOG_MODEL을 사용하여 모델을 W&B Artifacts에 저장한 경우 추가 트레이닝을 위해 또는 추론을 실행하기 위해 모델 가중치를 다운로드할 수 있습니다. 이전과 동일한 Hugging Face 아키텍처에 다시 로드하기만 하면 됩니다.
# 새 Run 만들기
with wandb.init(project="amazon_sentiment_analysis") as run:
# Artifact 이름 및 버전 전달
my_model_name = "model-bert-base-high-lr:latest"
my_model_artifact = run.use_artifact(my_model_name)
# 모델 가중치를 폴더에 다운로드하고 경로 반환
model_dir = my_model_artifact.download()
# 동일한 모델 클래스를 사용하여 해당 폴더에서 Hugging Face 모델 로드
model = AutoModelForSequenceClassification.from_pretrained(
model_dir, num_labels=num_labels
)
# 추가 트레이닝 또는 추론 실행
체크포인트에서 트레이닝을 재개하는 방법은 무엇인가요?
WANDB_LOG_MODEL='checkpoint'를 설정한 경우 model_dir을 TrainingArguments의 model_name_or_path 인수로 사용하고 resume_from_checkpoint=True를 Trainer에 전달하여 트레이닝을 재개할 수도 있습니다.
last_run_id = "xxxxxxxx" # wandb Workspace에서 run_id 가져오기
# run_id에서 W&B Run 재개
with wandb.init(
project=os.environ["WANDB_PROJECT"],
id=last_run_id,
resume="must",
) as run:
# Artifact를 Run에 연결
my_checkpoint_name = f"checkpoint-{last_run_id}:latest"
my_checkpoint_artifact = run.use_artifact(my_model_name)
# 체크포인트를 폴더에 다운로드하고 경로 반환
checkpoint_dir = my_checkpoint_artifact.download()
# 모델 및 Trainer 다시 초기화
model = AutoModelForSequenceClassification.from_pretrained(
"<model_name>", num_labels=num_labels
)
# 멋진 트레이닝 인수
training_args = TrainingArguments()
trainer = Trainer(model=model, args=training_args)
# 체크포인트 디렉터리를 사용하여 체크포인트에서 트레이닝을 재개해야 합니다.
trainer.train(resume_from_checkpoint=checkpoint_dir)
트레이닝 중에 평가 샘플을 로깅하고 보는 방법
Transformers Trainer를 통해 W&B에 로깅하는 것은 Transformers 라이브러리의 WandbCallback에서 처리합니다. Hugging Face 로깅을 사용자 지정해야 하는 경우 WandbCallback을 서브클래싱하고 Trainer 클래스의 추가적인 메서드를 활용하는 추가적인 기능을 추가하여 이 콜백을 수정할 수 있습니다.
아래는 이 새로운 콜백을 HF Trainer에 추가하는 일반적인 패턴이며, 아래에는 평가 출력을 W&B Table에 로깅하는 코드 완성 예제가 있습니다.
# Trainer를 정상적으로 인스턴스화
trainer = Trainer()
# Trainer 오브젝트를 전달하여 새로운 로깅 콜백 인스턴스화
evals_callback = WandbEvalsCallback(trainer, tokenizer, ...)
# Trainer에 콜백 추가
trainer.add_callback(evals_callback)
# Trainer 트레이닝을 정상적으로 시작
trainer.train()
트레이닝 중 평가 샘플 보기
다음 섹션에서는 모델 예측을 실행하고 트레이닝 중에 평가 샘플을 W&B Table에 로깅하도록 WandbCallback을 사용자 지정하는 방법을 보여줍니다. Trainer 콜백의 on_evaluate 메서드를 사용하여 모든 eval_steps에서 수행합니다.
여기서는 토크나이저를 사용하여 모델 출력에서 예측 및 레이블을 디코딩하는 decode_predictions 함수를 작성했습니다.
그런 다음 예측 및 레이블에서 pandas DataFrame을 만들고 DataFrame에 epoch 열을 추가합니다.
마지막으로 DataFrame에서 wandb.Table을 만들고 wandb에 로깅합니다.
또한 예측을 freq 에포크마다 로깅하여 로깅 빈도를 제어할 수 있습니다.
참고: 일반적인 WandbCallback과 달리 이 사용자 지정 콜백은 Trainer를 인스턴스화한 후에 Trainer에 추가해야 하며 Trainer 초기화 중에는 추가하면 안 됩니다.
Trainer 인스턴스는 초기화 중에 콜백에 전달되기 때문입니다.
from transformers.integrations import WandbCallback
import pandas as pd
def decode_predictions(tokenizer, predictions):
labels = tokenizer.batch_decode(predictions.label_ids)
logits = predictions.predictions.argmax(axis=-1)
prediction_text = tokenizer.batch_decode(logits)
return {"labels": labels, "predictions": prediction_text}
class WandbPredictionProgressCallback(WandbCallback):
"""트레이닝 중에 모델 예측을 로깅하는 사용자 지정 WandbCallback입니다.
이 콜백은 트레이닝 중 각 로깅 단계에서 모델 예측과 레이블을 wandb.Table에 로깅합니다.
트레이닝이 진행됨에 따라 모델 예측을 시각화할 수 있습니다.
특성:
trainer (Trainer): Hugging Face Trainer 인스턴스입니다.
tokenizer (AutoTokenizer): 모델과 연결된 토크나이저입니다.
sample_dataset (Dataset): 예측 생성을 위한 유효성 검사 데이터셋의 서브셋입니다.
num_samples (int, optional): 예측 생성을 위해 유효성 검사 데이터셋에서 선택할 샘플 수입니다. 기본값은 100입니다.
freq (int, optional): 로깅 빈도입니다. 기본값은 2입니다.
"""
def __init__(self, trainer, tokenizer, val_dataset, num_samples=100, freq=2):
"""WandbPredictionProgressCallback 인스턴스를 초기화합니다.
인수:
trainer (Trainer): Hugging Face Trainer 인스턴스입니다.
tokenizer (AutoTokenizer): 모델과 연결된 토크나이저입니다.
val_dataset (Dataset): 유효성 검사 데이터셋입니다.
num_samples (int, optional): 예측 생성을 위해 유효성 검사 데이터셋에서 선택할 샘플 수입니다.
기본값은 100입니다.
freq (int, optional): 로깅 빈도입니다. 기본값은 2입니다.
"""
super().__init__()
self.trainer = trainer
self.tokenizer = tokenizer
self.sample_dataset = val_dataset.select(range(num_samples))
self.freq = freq
def on_evaluate(self, args, state, control, **kwargs):
super().on_evaluate(args, state, control, **kwargs)
# `freq` 에포크마다 예측을 로깅하여 로깅 빈도 제어
if state.epoch % self.freq == 0:
# 예측 생성
predictions = self.trainer.predict(self.sample_dataset)
# 예측 및 레이블 디코딩
predictions = decode_predictions(self.tokenizer, predictions)
# wandb.Table에 예측 추가
predictions_df = pd.DataFrame(predictions)
predictions_df["epoch"] = state.epoch
records_table = self._wandb.Table(dataframe=predictions_df)
# 테이블을 wandb에 로깅
self._wandb.log({"sample_predictions": records_table})
# 먼저 Trainer 인스턴스화
trainer = Trainer(
model=model,
args=training_args,
train_dataset=lm_datasets["train"],
eval_dataset=lm_datasets["validation"],
)
# WandbPredictionProgressCallback 인스턴스화
progress_callback = WandbPredictionProgressCallback(
trainer=trainer,
tokenizer=tokenizer,
val_dataset=lm_dataset["validation"],
num_samples=10,
freq=2,
)
# Trainer에 콜백 추가
trainer.add_callback(progress_callback)
자세한 예제는 이 colab을 참조하세요.
어떤 추가 W&B 설정이 제공되나요?
환경 변수를 설정하여 Trainer로 로깅되는 항목을 추가로 구성할 수 있습니다. W&B 환경 변수의 전체 목록은 여기에서 찾을 수 있습니다.
| 환경 변수 | 사용법 |
|---|---|
WANDB_PROJECT |
프로젝트 이름 지정(기본값: huggingface) |
WANDB_LOG_MODEL |
모델 체크포인트를 W&B Artifact로 로깅(기본값:
|
WANDB_WATCH |
모델 그레이디언트, 파라미터 또는 둘 다를 로깅할지 여부 설정
|
WANDB_DISABLED |
true로 설정하여 로깅을 완전히 끕니다(기본값: false) |
WANDB_SILENT |
true로 설정하여 wandb에서 인쇄된 출력을 표시하지 않습니다(기본값: false) |
WANDB_WATCH=all
WANDB_SILENT=true
%env WANDB_WATCH=all
%env WANDB_SILENT=true
wandb.init를 사용자 지정하는 방법은 무엇인가요?
Trainer가 사용하는 WandbCallback은 Trainer가 초기화될 때 내부적으로 wandb.init를 호출합니다. 또는 Trainer를 초기화하기 전에 wandb.init를 호출하여 Run을 수동으로 설정할 수 있습니다. 이렇게 하면 W&B Run 구성을 완전히 제어할 수 있습니다.
init에 전달할 수 있는 예는 아래와 같습니다. wandb.init를 사용하는 방법에 대한 자세한 내용은 참조 설명서를 확인하세요.
wandb.init(
project="amazon_sentiment_analysis",
name="bert-base-high-lr",
tags=["baseline", "high-lr"],
group="bert",
)
추가 자료
다음은 Transformer 및 W&B 관련 기사 6가지입니다.
Hugging Face Transformers의 하이퍼파라미터 최적화
- Hugging Face Transformers의 하이퍼파라미터 최적화를 위한 세 가지 전략(그리드 검색, 베이지안 최적화 및 모집단 기반 트레이닝)을 비교합니다.
- Hugging Face Transformers의 표준 uncased BERT 모델을 사용하고 SuperGLUE 벤치마크에서 RTE 데이터셋을 파인튜닝하려고 합니다.
- 결과는 모집단 기반 트레이닝이 Hugging Face Transformer 모델의 하이퍼파라미터 최적화에 가장 효과적인 접근 방식임을 보여줍니다.
전체 리포트는 여기에서 읽어보세요.
Hugging Tweets: 트윗 생성을 위한 모델 트레이닝
- 이 기사에서 작성자는 5분 안에 모든 사람의 트윗에서 사전 트레이닝된 GPT2 HuggingFace Transformer 모델을 파인튜닝하는 방법을 보여줍니다.
- 이 모델은 다음 파이프라인을 사용합니다. 트윗 다운로드, 데이터셋 최적화, 초기 실험, 사용자 간 손실 비교, 모델 파인튜닝.
전체 리포트는 여기에서 읽어보세요.
Hugging Face BERT 및 WB를 사용한 문장 분류
- 이 기사에서는 자연어 처리의 최근 혁신의 힘을 활용하여 문장 분류기를 구축하고 NLP에 대한 전이 학습 애플리케이션에 중점을 둡니다.
- 우리는 단일 문장 분류를 위해 CoLA(Corpus of Linguistic Acceptability) 데이터셋을 사용합니다. 이 데이터셋은 문법적으로 올바르거나 올바르지 않은 것으로 레이블이 지정된 일련의 문장으로, 2018년 5월에 처음 게시되었습니다.
- Google의 BERT를 사용하여 다양한 NLP 작업에서 최소한의 노력으로 고성능 모델을 만듭니다.
전체 리포트는 여기에서 읽어보세요.
Hugging Face 모델 성능 추적에 대한 단계별 가이드
- W&B와 Hugging Face Transformers를 사용하여 BERT보다 40% 작지만 BERT 정확도의 97%를 유지하는 Transformer인 DistilBERT를 GLUE 벤치마크에서 트레이닝합니다.
- GLUE 벤치마크는 NLP 모델 트레이닝을 위한 9개의 데이터셋 및 작업 모음입니다.
전체 리포트는 여기에서 읽어보세요.
HuggingFace의 조기 중단 예제
- 조기 중단 정규화를 사용하여 Hugging Face Transformer를 파인튜닝하는 것은 PyTorch 또는 TensorFlow에서 기본적으로 수행할 수 있습니다.
- TensorFlow에서 EarlyStopping 콜백을 사용하는 것은
tf.keras.callbacks.EarlyStopping콜백을 사용하는 것과 간단합니다. - PyTorch에는 즉시 사용 가능한 조기 중단 메서드는 없지만 GitHub Gist에서 작업 조기 중단 훅을 사용할 수 있습니다.
전체 리포트는 여기에서 읽어보세요.
사용자 지정 데이터셋에서 Hugging Face Transformers를 파인튜닝하는 방법
사용자 지정 IMDB 데이터셋에서 감정 분석(이진 분류)을 위해 DistilBERT Transformer를 파인튜닝합니다.
전체 리포트는 여기에서 읽어보세요.
도움을 받거나 기능 요청
Hugging Face W&B 통합에 대한 문제, 질문 또는 기능 요청이 있는 경우 Hugging Face 포럼의 이 스레드에 게시하거나 Hugging Face Transformers GitHub 리포에 문제를 여유롭게 게시하세요.
피드백
이 페이지가 도움이 되었나요?
Glad to hear it! If you have more to say, please let us know.
Sorry to hear that. Please tell us how we can improve.