Weave と Models インテグレーション デモ
3 minute read
このノートブックは、W&B Weave を W&B Models と一緒に使用する方法を示しています。具体的には、2つの異なるチームを検討しています。
- モデルチーム: モデル作成チームは、新しいチャットモデル (Llama 3.2) をファインチューニングし、W&B Models を使用してそれをレジストリに保存します。
- アプリチーム: アプリ開発チームはチャットモデルを取得して、新しいRAGチャットボットを作成および評価するために W&B Weave を使用します。
W&B Models と W&B Weave のパブリックワークスペースを こちら から見つけることができます。
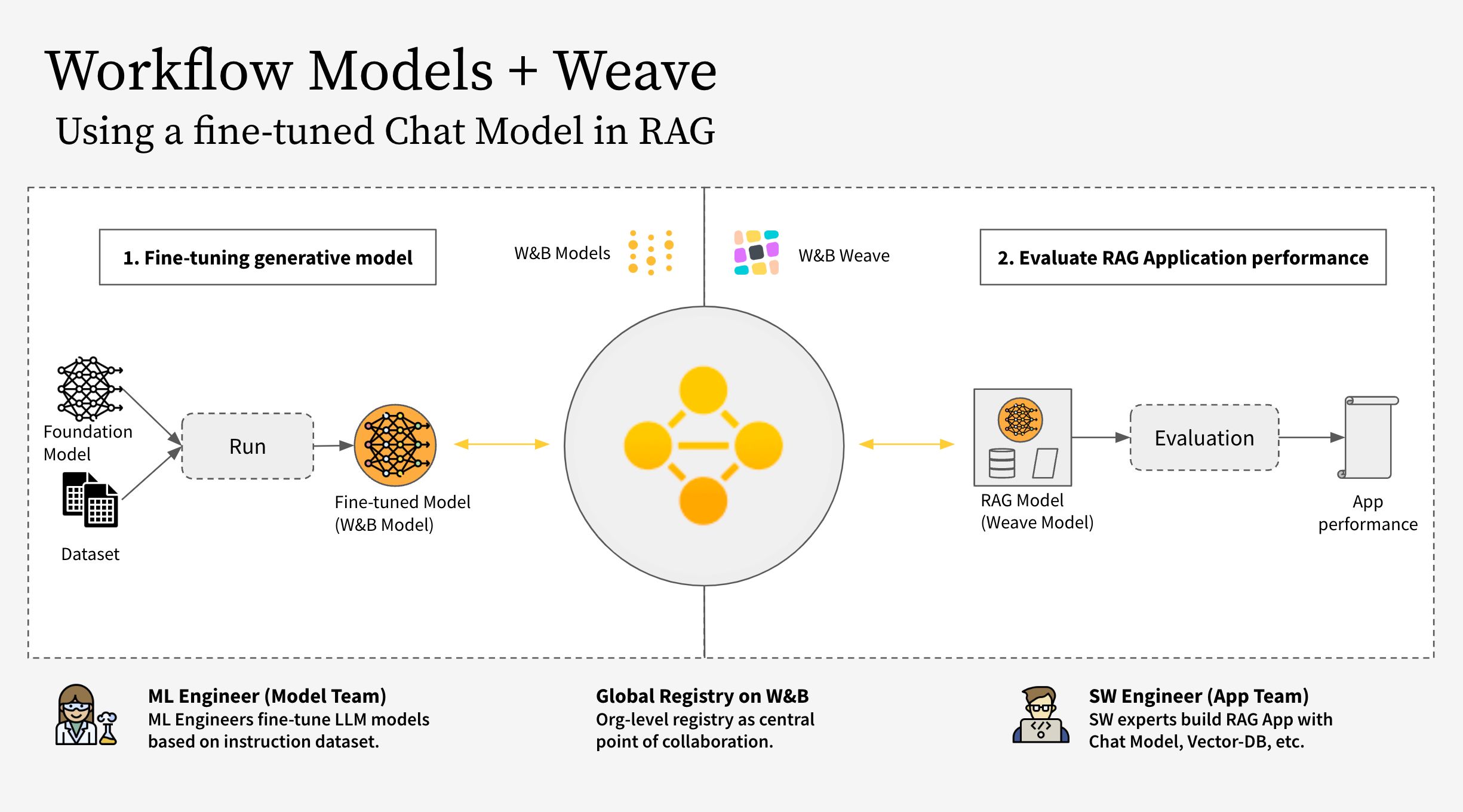
ワークフローは次のステップをカバーしています:
- RAGアプリのコードを W&B Weave で計測する
- LLM(Llama 3.2 など、他のLLMに置き換えることも可能)をファインチューニングし、W&B Models でトラッキングする
- ファインチューニングされたモデルを W&B Registry にログする
- 新しいファインチューニングされたモデルを使用してRAGアプリを実装し、W&B Weave でアプリを評価する
- 結果に満足したら、更新されたRAGアプリの参照を W&B Registry に保存する
注意:
以下で参照される RagModel は、完全なRAGアプリと考えられるトップレベルの weave.Model です。これは ChatModel、ベクトルデータベース、プロンプトを含みます。ChatModel もまた別の weave.Model であり、W&B Registry からアーティファクトをダウンロードする機能を持つコードを含んでおり、RagModel の一部として任意の他のチャットモデルをサポートするために変更可能です。詳細は Weaveでの完全なモデル を参照してください。
1. セットアップ
まず、weave と wandb をインストールし、APIキーでログインします。APIキーは https://wandb.ai/settings で作成し、表示できます。
pip install weave wandb
import wandb
import weave
import pandas as pd
PROJECT = "weave-cookboook-demo"
ENTITY = "wandb-smle"
wandb.login()
weave.init(ENTITY + "/" + PROJECT)
2. アーティファクトに基づく ChatModel を作成する
Registry からファインチューニングされたチャットモデルを取得し、weave.Model を作成して次のステップでRagModelに直接プラグインします。既存の ChatModel と同じパラメータを取りますが、init と predict は変更されます。
pip install unsloth
pip uninstall unsloth -y && pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
モデルチームは unsloth ライブラリを使用して異なる Llama-3.2 モデルをファインチューニングし、より高速にしました。したがって、特殊な unsloth.FastLanguageModel または peft.AutoPeftModelForCausalLM モデルとアダプターを使用してモデルをダウンロードする必要があります。Registry の「使用」タブからロードコードをコピーして model_post_init に貼り付けます。
import weave
from pydantic import PrivateAttr
from typing import Any, List, Dict, Optional
from unsloth import FastLanguageModel
import torch
class UnslothLoRAChatModel(weave.Model):
"""
モデル名だけでなく、より多くのパラメータを保存し、バージョン管理するための追加の ChatModel クラスを定義します。
これにより、特定のパラメータでファインチューニングが可能になります。
"""
chat_model: str
cm_temperature: float
cm_max_new_tokens: int
cm_quantize: bool
inference_batch_size: int
dtype: Any
device: str
_model: Any = PrivateAttr()
_tokenizer: Any = PrivateAttr()
def model_post_init(self, __context):
# Registry の「使用」タブからこれを貼り付けます
run = wandb.init(project=PROJECT, job_type="model_download")
artifact = run.use_artifact(f"{self.chat_model}")
model_path = artifact.download()
# unsloth バージョン(ネイティブで2倍の速度で推論)
self._model, self._tokenizer = FastLanguageModel.from_pretrained(
model_name=model_path,
max_seq_length=self.cm_max_new_tokens,
dtype=self.dtype,
load_in_4bit=self.cm_quantize,
)
FastLanguageModel.for_inference(self._model)
@weave.op()
async def predict(self, query: List[str]) -> dict:
# 生成プロンプトを追加 = true - 生成するために必須
input_ids = self._tokenizer.apply_chat_template(
query,
tokenize=True,
add_generation_prompt=True,
return_tensors="pt",
).to("cuda")
output_ids = self._model.generate(
input_ids=input_ids,
max_new_tokens=64,
use_cache=True,
temperature=1.5,
min_p=0.1,
)
decoded_outputs = self._tokenizer.batch_decode(
output_ids[0][input_ids.shape[1] :], skip_special_tokens=True
)
return "".join(decoded_outputs).strip()
次に、Registry から特定のリンクで新しいモデルを作成します:
MODEL_REG_URL = "wandb32/wandb-registry-RAG Chat Models/Finetuned Llama-3.2:v3"
max_seq_length = 2048
dtype = None
load_in_4bit = True
new_chat_model = UnslothLoRAChatModel(
name="UnslothLoRAChatModelRag",
chat_model=MODEL_REG_URL,
cm_temperature=1.0,
cm_max_new_tokens=max_seq_length,
cm_quantize=load_in_4bit,
inference_batch_size=max_seq_length,
dtype=dtype,
device="auto",
)
そして最後に非同期で評価を実行します:
await new_chat_model.predict(
[{"role": "user", "content": "What is the capital of Germany?"}]
)
3. 新しい ChatModel バージョンを RagModel に統合する
ファインチューニングされたチャットモデルを使用してRAGアプリを構築することは、特に会話型AIシステムの性能と多様性を向上させる上でいくつかの利点を提供します。
現在のWeaveプロジェクトから RagModel を取得し、新しい ChatModel に交換します。他のコンポーネント(VDB、プロンプトなど)を変更または再作成する必要はありません!

pip install litellm faiss-gpu
RagModel = weave.ref(
"weave:///wandb-smle/weave-cookboook-demo/object/RagModel:cqRaGKcxutBWXyM0fCGTR1Yk2mISLsNari4wlGTwERo"
).get()
# MAGIC: chat_model を交換して新しいバージョンを公開する(他のRAGコンポーネントについて心配する必要はありません)
RagModel.chat_model = new_chat_model
# 予測中に参照されるように新しいバージョンを最初に公開します
PUB_REFERENCE = weave.publish(RagModel, "RagModel")
await RagModel.predict("When was the first conference on climate change?")
4. 既存のモデルの run に接続する新しい weave.Evaluation を実行する
最後に、既存の weave.Evaluation 上で新しい RagModel を評価します。統合をできるだけシンプルにするために、以下の変更を含みます。
モデルの観点から:
- Registry からモデルを取得すると新しい
wandb.runが作成され、チャットモデルのE2Eリネージの一部になります - 現在の評価IDを持つTrace IDを実行設定に追加し、モデルチームがリンクをクリックして対応する Weave ページに移動できるようにします
Weave の観点から:
- アーティファクト / レジストリリンクを
ChatModel(つまりRagModel)への入力として保存します weave.attributesを使用して run.id をトレースの追加列として保存します
# MAGIC: 評価データセットや評価スコアラーと一緒に評価を取得して使用します
WEAVE_EVAL = "weave:///wandb-smle/weave-cookboook-demo/object/climate_rag_eval:ntRX6qn3Tx6w3UEVZXdhIh1BWGh7uXcQpOQnIuvnSgo"
climate_rag_eval = weave.ref(WEAVE_EVAL).get()
with weave.attributes({"wandb-run-id": wandb.run.id}):
# 結果およびそのコールを取得するために.evaluate.call 属性を使用して評価トレースを Models に保存します
summary, call = await climate_rag_eval.evaluate.call(climate_rag_eval, ` RagModel `)
5. レジストリに新しいRAGモデルを保存する
新しいRAGモデルを効果的に共有するために、参照アーティファクトとしてそれをレジストリにプッシュし、weaveバージョンをエイリアスとして追加します。
MODELS_OBJECT_VERSION = PUB_REFERENCE.digest # weave オブジェクトバージョン
MODELS_OBJECT_NAME = PUB_REFERENCE.name # weave オブジェクト名
models_url = f"https://wandb.ai/{ENTITY}/{PROJECT}/weave/objects/{MODELS_OBJECT_NAME}/versions/{MODELS_OBJECT_VERSION}"
models_link = (
f"weave:///{ENTITY}/{PROJECT}/object/{MODELS_OBJECT_NAME}:{MODELS_OBJECT_VERSION}"
)
with wandb.init(project=PROJECT, entity=ENTITY) as run:
# 新しいアーティファクトを作成
artifact_model = wandb.Artifact(
name="RagModel",
type="model",
description="Models Link from RagModel in Weave",
metadata={"url": models_url},
)
artifact_model.add_reference(models_link, name="model", checksum=False)
# 新しいアーティファクトをログする
run.log_artifact(artifact_model, aliases=[MODELS_OBJECT_VERSION])
# レジストリにリンクする
run.link_artifact(
artifact_model, target_path="wandb32/wandb-registry-RAG Models/RAG Model"
)
フィードバック
このページは役に立ちましたか?
Glad to hear it! If you have more to say, please let us know.
Sorry to hear that. Please tell us how we can improve.