モデルレジストリ
モデルレジストリでトレーニングからプロダクションまでのモデルライフサイクルを管理する
W&B は最終的に W&B Model Registry のサポートを停止します。ユーザーは代わりにモデルのアーティファクトバージョンをリンクして共有するために W&B Registry を使用することを推奨されます。W&B Registry は、旧 W&B Model Registry の機能を拡張します。W&B Registry について詳しくは、Registry docs をご覧ください。
W&B は近い将来、旧 Model Registry にリンクされた既存のモデルアーティファクトを新しい W&B Registry へ移行する予定です。移行プロセスに関する情報は、Migrating from legacy Model Registry をご覧ください。
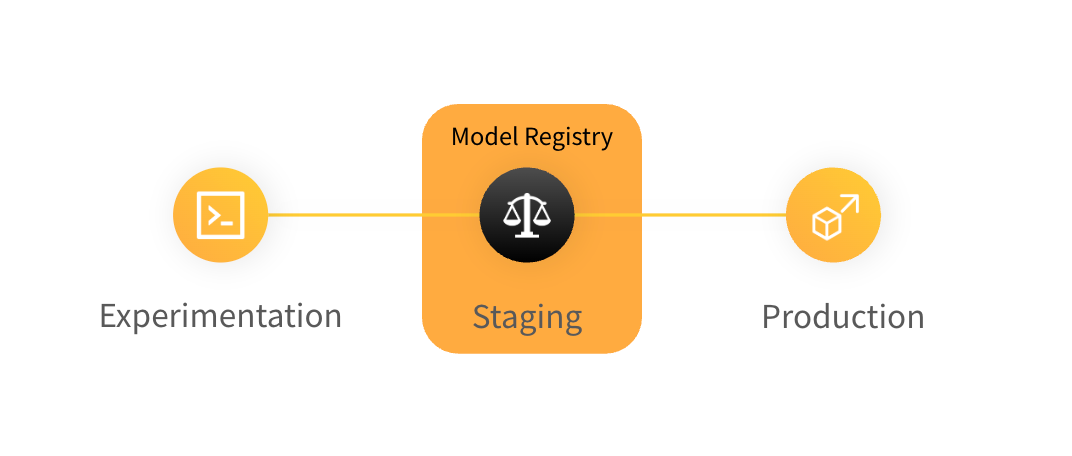
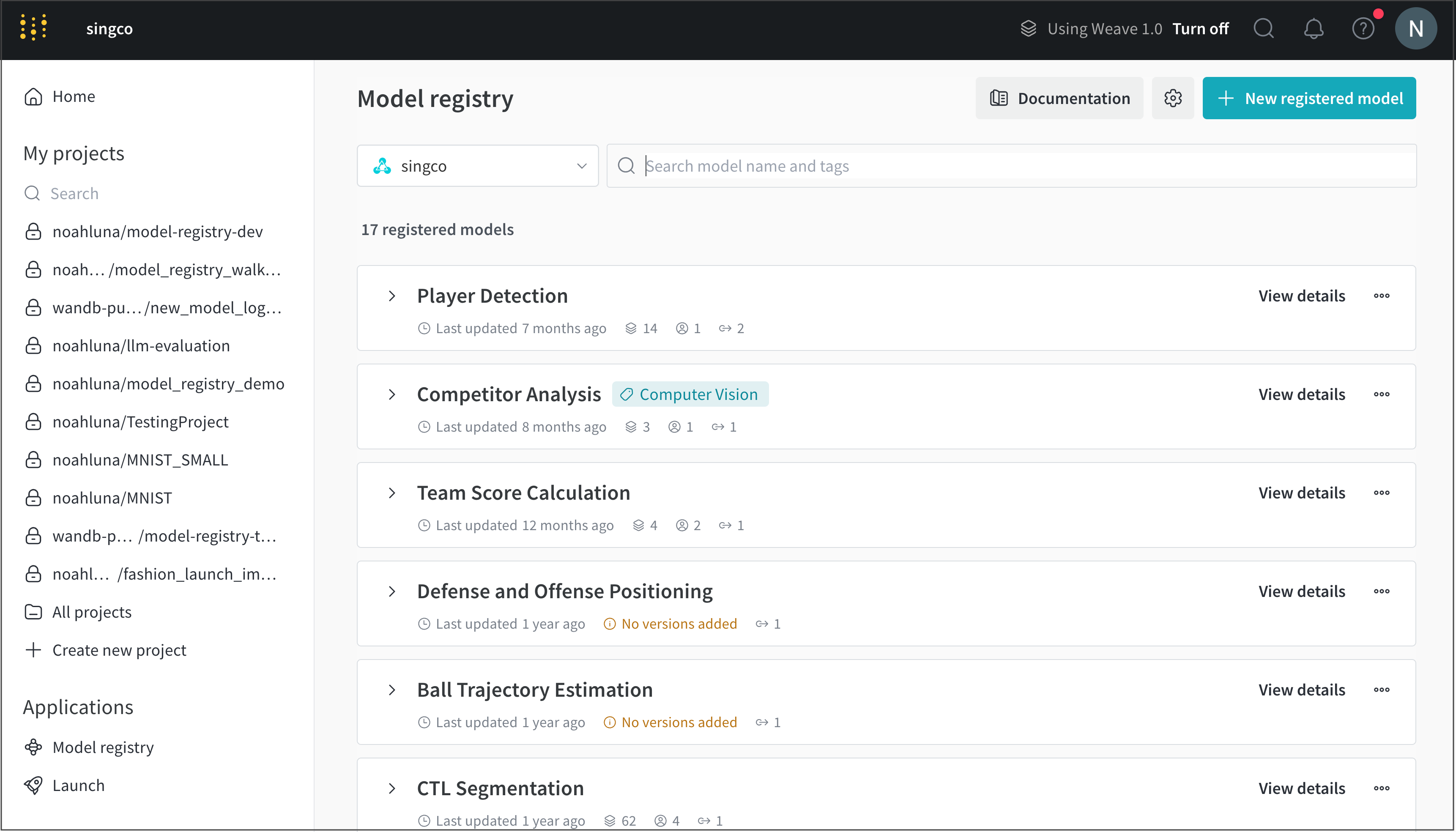
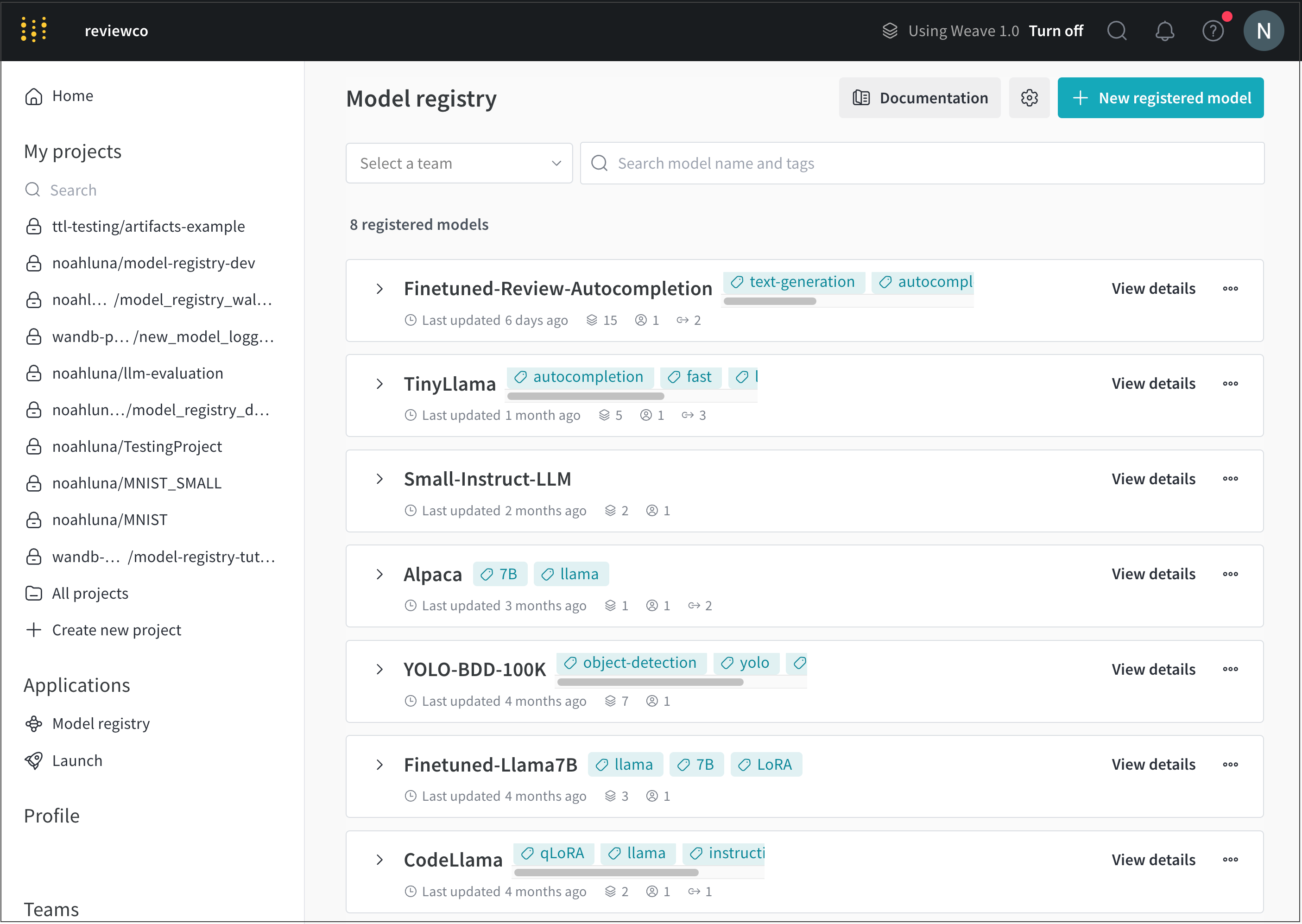
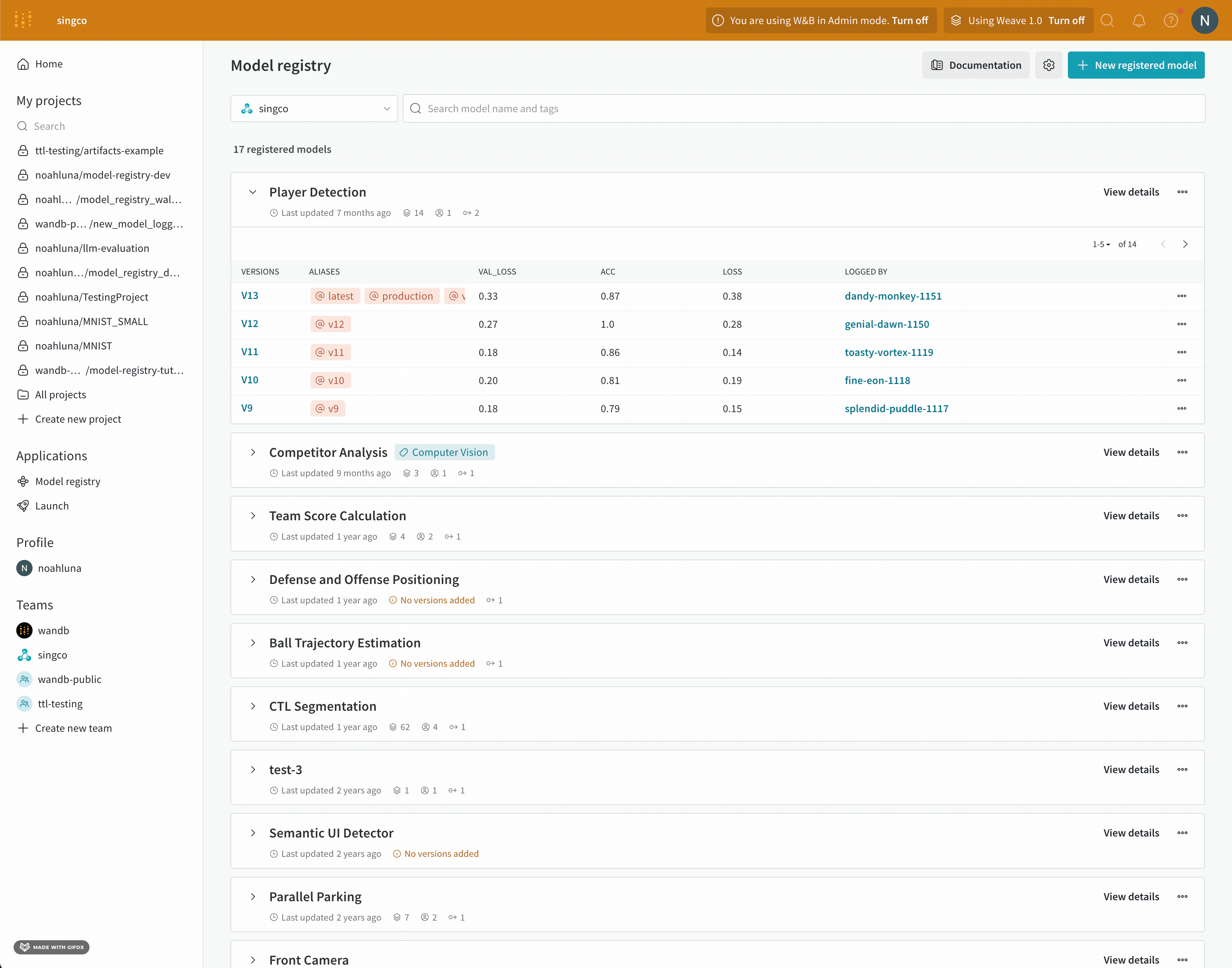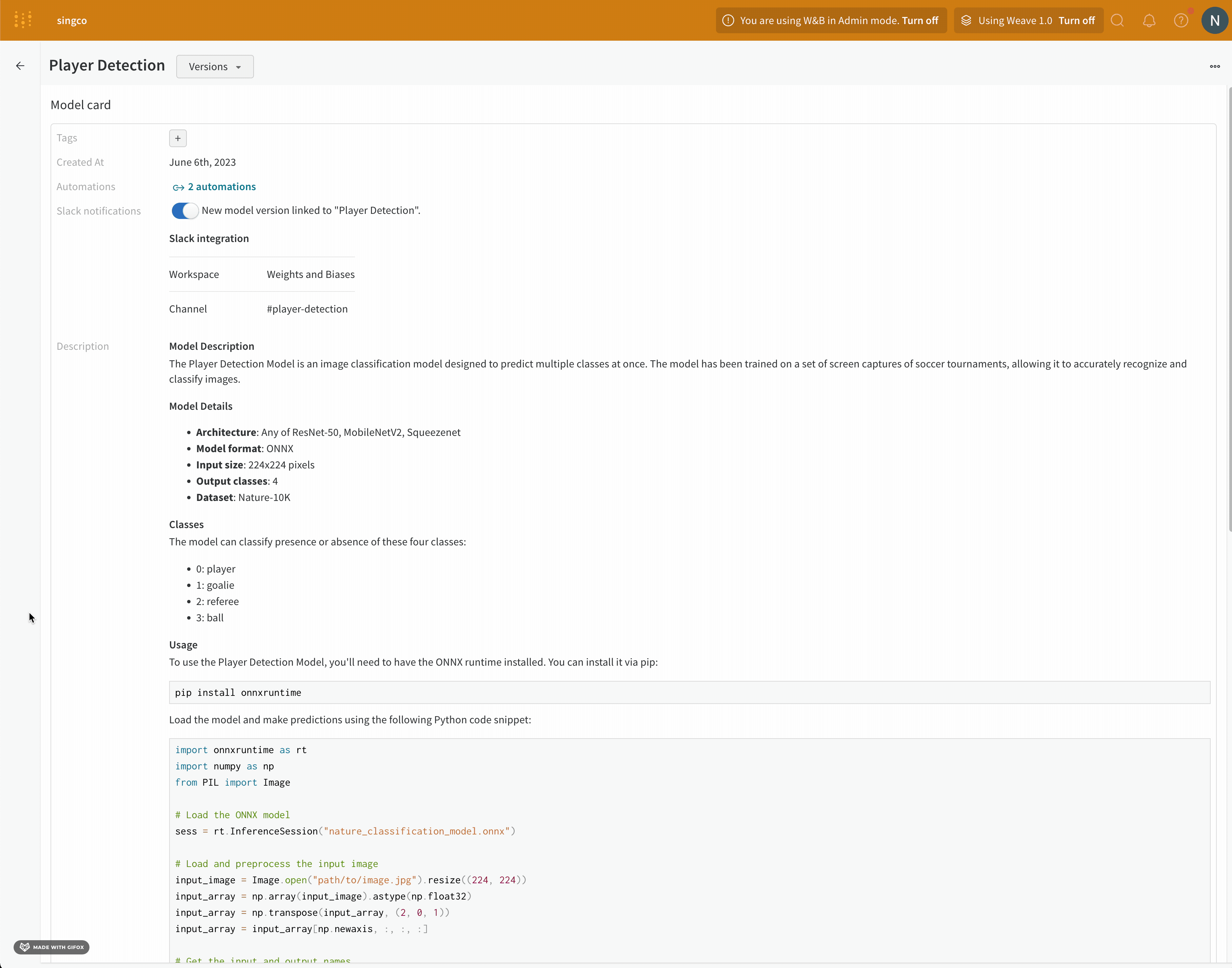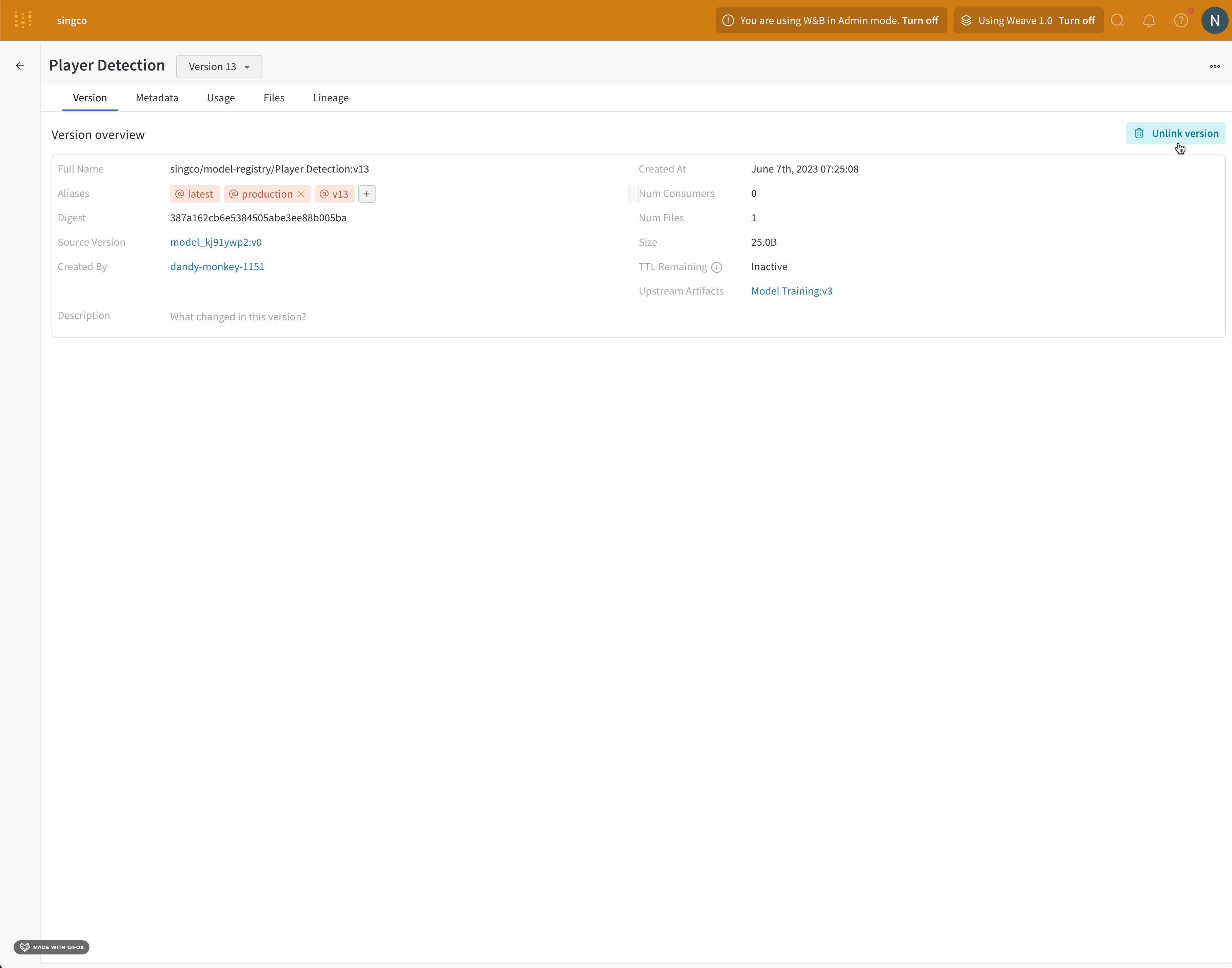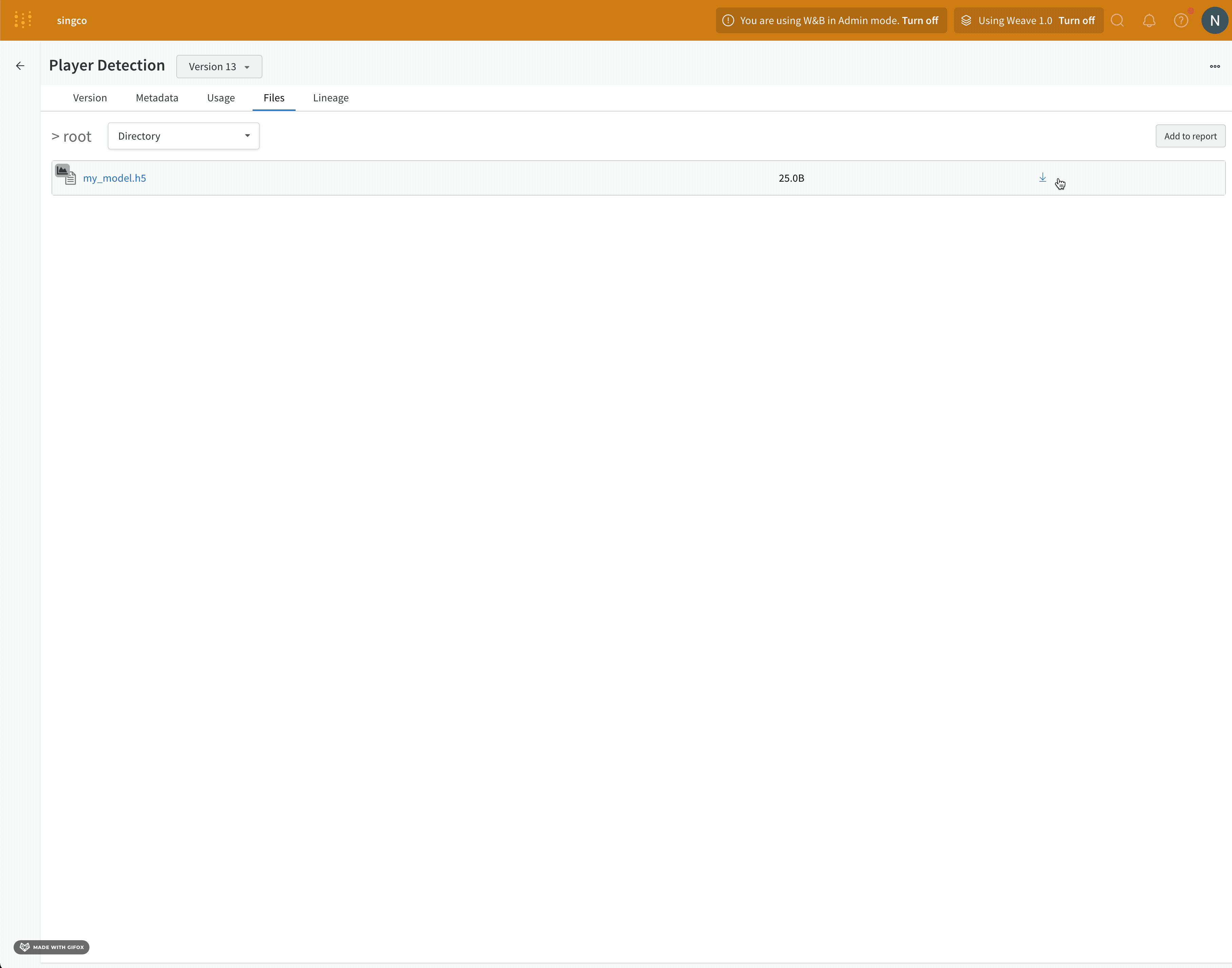
W&B Model Registry は、チームのトレーニングされたモデルを収納し、MLプラクティショナーがプロダクションに向けた候補を公開し、下流のチームや関係者に消費させることができます。これは、ステージング/候補モデルを収容し、ステージングに関連するワークフローを管理するために使用されます。
W&B Model Registry を使用すると、以下が可能です:
仕組み
ステージングされたモデルを数ステップで追跡し、管理します。
モデルバージョンをログする :トレーニングスクリプトに数行のコードを追加して、モデルファイルをアーティファクトとして W&B に保存します。パフォーマンスを比較する :ライブチャートをチェックして、トレーニングと検証からのメトリクスやサンプル予測を比較します。どのモデルバージョンが最もよくパフォーマンスしたかを特定します。レジストリにリンクする :ベストなモデルバージョンを登録済みモデルにリンクしてブックマークします。これは Python でプログラム的に、または W&B UI でインタラクティブに行うことができます。
以下のコードスニペットは、モデルを Model Registry にログし、リンクする方法を示しています:
import wandb
import random
# 新しい W&B run を開始
run = wandb. init(project= "models_quickstart" )
# モデルメトリクスをシミュレーションしてログする
run. log({"acc" : random. random()})
# シミュレートされたモデルファイルを作成
with open("my_model.h5" , "w" ) as f:
f. write("Model: " + str(random. random()))
# モデルを Model Registry にログし、リンクする
run. link_model(path= "./my_model.h5" , registered_model_name= "MNIST" )
run. finish()
モデルの移行を CI/CD ワークフローに接続する :候補モデルをワークフローステージを通して移行し、下流のアクションをオートメーション化する ことを Webhook を使って行います。
開始方法
ユースケースに応じて、W&B Models を使い始めるための以下のリソースを探ります。
2 部構成のビデオシリーズを確認:
モデルのログと登録 モデルの消費と下流プロセスのオートメーション化 in the Model Registry.
モデルウォークスルー を読み、W&B Python SDK コマンドを使用してデータセットアーティファクトを作成、追跡、および使用する手順を確認します。以下について学ぶ:
Model Registry があなたの ML ワークフローにどのようにフィットし、モデル管理のためにそれを使用することの利点についての この レポートを確認します。
W&B の Enterprise Model Management コースを受講し、以下を学びます:
W&B Model Registry を使って、モデルを管理、バージョン化し、リネージを追跡し、様々なライフサイクルステージを通じてモデルを推進する方法。
Webhook を使ってモデル管理ワークフローをオートメーション化する方法。
モデル評価、監視、デプロイメントのために Model Registry が外部 ML システムやツールとどのように統合されているかを確認する。
1 - Tutorial: W&B を使ったモデル管理
W&B を活用したモデル管理の使い方を学ぶ
W&B にモデルをログする方法を示す次のウォークスルーに従ってください。このウォークスルーの終わりまでに次のことができるようになります:
MNIST データセットと Keras フレームワークを使用してモデルを作成およびトレーニングします。
トレーニングしたモデルを W&B プロジェクトにログします。
作成したモデルの依存関係として使用したデータセットをマークします。
モデルを W&B Registry にリンクします。
レジストリにリンクしたモデルのパフォーマンスを評価します。
モデルバージョンをプロダクション用に準備完了としてマークします。
このガイドで提示された順にコードスニペットをコピーしてください。
モデルレジストリに固有でないコードは折りたたみ可能なセルに隠されています。
セットアップ
始める前に、このウォークスルーに必要な Python の依存関係をインポートします:
import wandb
import numpy as np
from tensorflow import keras
from tensorflow.keras import layers
from wandb.integration.keras import WandbMetricsLogger
from sklearn.model_selection import train_test_split
entity 変数に W&B エンティティを指定します:
データセット アーティファクトを作成する
まず、データセットを作成します。次のコードスニペットは、MNIST データセットをダウンロードする関数を作成します:
def generate_raw_data (train_size= 6000 ):
eval_size = int(train_size / 6 )
(x_train, y_train), (x_eval, y_eval) = keras. datasets. mnist. load_data()
x_train = x_train. astype("float32" ) / 255
x_eval = x_eval. astype("float32" ) / 255
x_train = np. expand_dims(x_train, - 1 )
x_eval = np. expand_dims(x_eval, - 1 )
print("Generated {} rows of training data." . format(train_size))
print("Generated {} rows of eval data." . format(eval_size))
return (x_train[:train_size], y_train[:train_size]), (
x_eval[:eval_size],
y_eval[:eval_size],
)
# データセットを作成
(x_train, y_train), (x_eval, y_eval) = generate_raw_data()
次に、データセットを W&B にアップロードします。これを行うには、artifact オブジェクトを作成し、そのアーティファクトにデータセットを追加します。
project = "model-registry-dev"
model_use_case_id = "mnist"
job_type = "build_dataset"
# W&B run を初期化
run = wandb. init(entity= entity, project= project, job_type= job_type)
# トレーニングデータ用に W&B Table を作成
train_table = wandb. Table(data= [], columns= [])
train_table. add_column("x_train" , x_train)
train_table. add_column("y_train" , y_train)
train_table. add_computed_columns(lambda ndx, row: {"img" : wandb. Image(row["x_train" ])})
# 評価データ用に W&B Table を作成
eval_table = wandb. Table(data= [], columns= [])
eval_table. add_column("x_eval" , x_eval)
eval_table. add_column("y_eval" , y_eval)
eval_table. add_computed_columns(lambda ndx, row: {"img" : wandb. Image(row["x_eval" ])})
# アーティファクトオブジェクトを作成
artifact_name = " {} _dataset" . format(model_use_case_id)
artifact = wandb. Artifact(name= artifact_name, type= "dataset" )
# wandb.WBValue オブジェクトをアーティファクトに追加
artifact. add(train_table, "train_table" )
artifact. add(eval_table, "eval_table" )
# アーティファクトに加えられた変更を永続化
artifact. save()
# W&B にこの run が完了したことを知らせます
run. finish()
アーティファクトにファイル(データセットなど)を保存することは、モデルの依存関係を追跡できるため、モデルをログに記録するという文脈で便利です。
モデルのトレーニング
前のステップで作成したアーティファクトデータセットを使用してモデルをトレーニングします。
データセットアーティファクトを run の入力として宣言
前のステップで作成したデータセットアーティファクトを W&B run の入力として宣言します。これにより、特定のモデルをトレーニングするために使用されたデータセット(およびデータセットのバージョン)を追跡できるため、モデルをログに記録するという文脈で特に便利です。W&B は収集された情報を使用して、lineage map を作成します。
use_artifact API を使用して、データセットアーティファクトを run の入力として宣言し、アーティファクト自体を取得します。
job_type = "train_model"
config = {
"optimizer" : "adam" ,
"batch_size" : 128 ,
"epochs" : 5 ,
"validation_split" : 0.1 ,
}
# W&B run を初期化
run = wandb. init(project= project, job_type= job_type, config= config)
# データセットアーティファクトを取得
version = "latest"
name = " {} : {} " . format(" {} _dataset" . format(model_use_case_id), version)
artifact = run. use_artifact(artifact_or_name= name)
# データフレームから特定のコンテンツを取得
train_table = artifact. get("train_table" )
x_train = train_table. get_column("x_train" , convert_to= "numpy" )
y_train = train_table. get_column("y_train" , convert_to= "numpy" )
モデルの入力と出力を追跡する方法の詳細については、Create model lineage mapを参照してください。
モデルの定義とトレーニング
このウォークスルーでは、Keras を使用して MNIST データセットから画像を分類するための 2D 畳み込みニューラルネットワーク (CNN) を定義します。
MNIST データに対する CNN のトレーニング
# 設定辞書から値を取得して変数に格納(アクセスしやすくするため)
num_classes = 10
input_shape = (28 , 28 , 1 )
loss = "categorical_crossentropy"
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
batch_size = run. config["batch_size" ]
epochs = run. config["epochs" ]
validation_split = run. config["validation_split" ]
# モデルアーキテクチャを作成
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# トレーニングデータのラベルを生成
y_train = keras. utils. to_categorical(y_train, num_classes)
# トレーニングセットとテストセットを作成
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size= 0.33 )
次に、モデルをトレーニングします:
# モデルをトレーニング
model. fit(
x= x_t,
y= y_t,
batch_size= batch_size,
epochs= epochs,
validation_data= (x_v, y_v),
callbacks= [WandbCallback(log_weights= True , log_evaluation= True )],
)
最後に、モデルをローカルマシンに保存します:
# モデルをローカルに保存
path = "model.h5"
model. save(path)
モデルを Model Registry にログし、リンクする
link_modelW&B Model Registry にリンクします。
path = "./model.h5"
registered_model_name = "MNIST-dev"
run. link_model(path= path, registered_model_name= registered_model_name)
run. finish()
指定した名前の registered-model-name がまだ存在しない場合、W&B は登録されたモデルを作成します。
オプションのパラメータに関する詳細は、API リファレンスガイドの link_model
モデルのパフォーマンスを評価する
複数のモデルのパフォーマンスを評価するのは一般的な手法です。
まず、前のステップで W&B に保存された評価データセットアーティファクトを取得します。
job_type = "evaluate_model"
# 初期化
run = wandb. init(project= project, entity= entity, job_type= job_type)
model_use_case_id = "mnist"
version = "latest"
# データセットアーティファクトを取得し、それを依存関係としてマーク
artifact = run. use_artifact(
" {} : {} " . format(" {} _dataset" . format(model_use_case_id), version)
)
# 必要なデータフレームを取得
eval_table = artifact. get("eval_table" )
x_eval = eval_table. get_column("x_eval" , convert_to= "numpy" )
y_eval = eval_table. get_column("y_eval" , convert_to= "numpy" )
評価したい W&B からのモデルバージョン をダウンロードします。use_model API を使用してモデルにアクセスし、ダウンロードします。
alias = "latest" # エイリアス
name = "mnist_model" # モデルアーティファクトの名前
# モデルにアクセスしダウンロードします。ダウンロードされたアーティファクトへのパスを返します
downloaded_model_path = run. use_model(name= f " { name} : { alias} " )
Keras モデルをロードし、損失を計算します:
model = keras. models. load_model(downloaded_model_path)
y_eval = keras. utils. to_categorical(y_eval, 10 )
(loss, _) = model. evaluate(x_eval, y_eval)
score = (loss, _)
最後に、損失のメトリクスを W&B run にログします:
# メトリクス、画像、テーブル、または評価に役立つデータをログします。
run. log(data= {"loss" : (loss, _)})
モデルバージョンを昇格する
モデルエイリアス
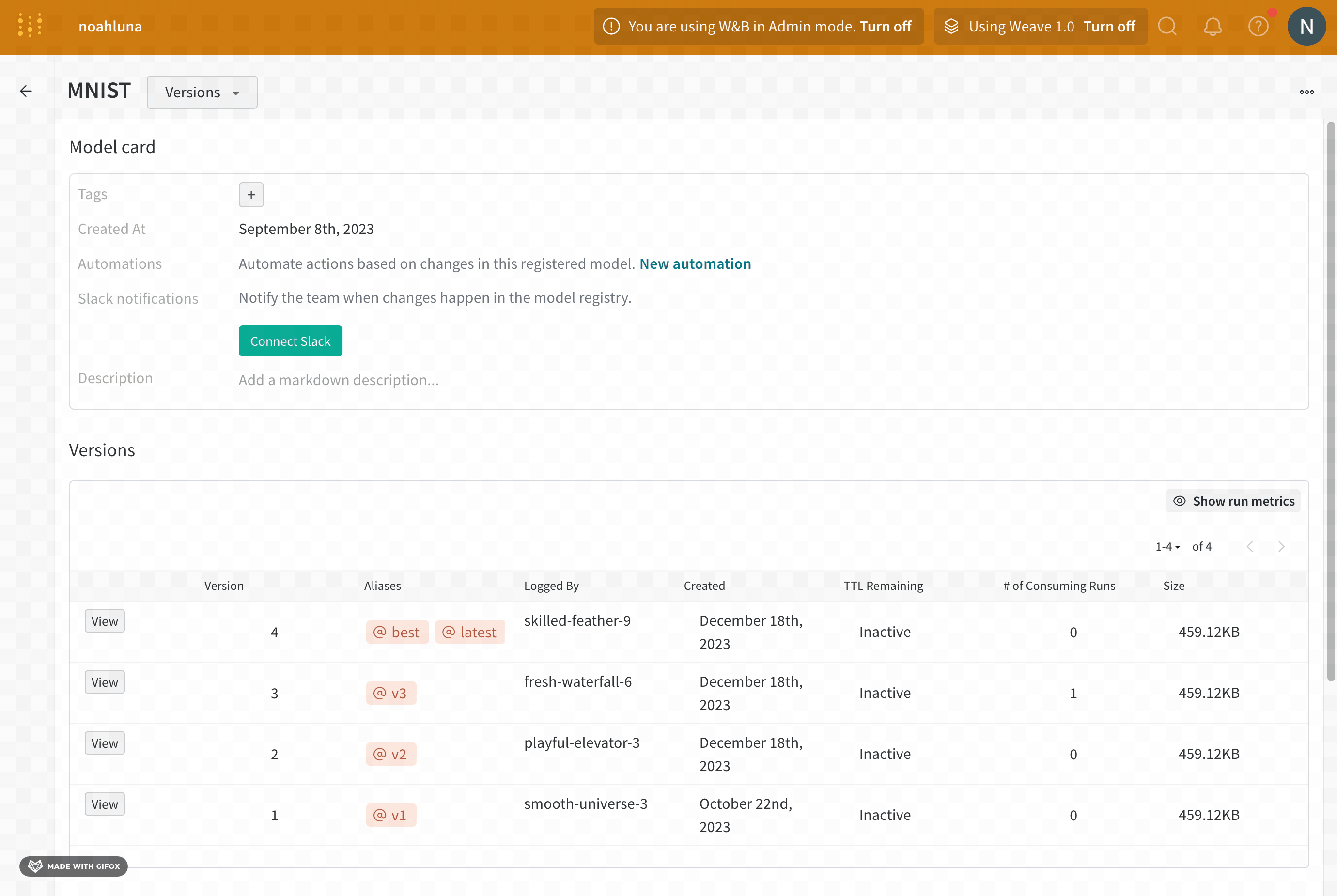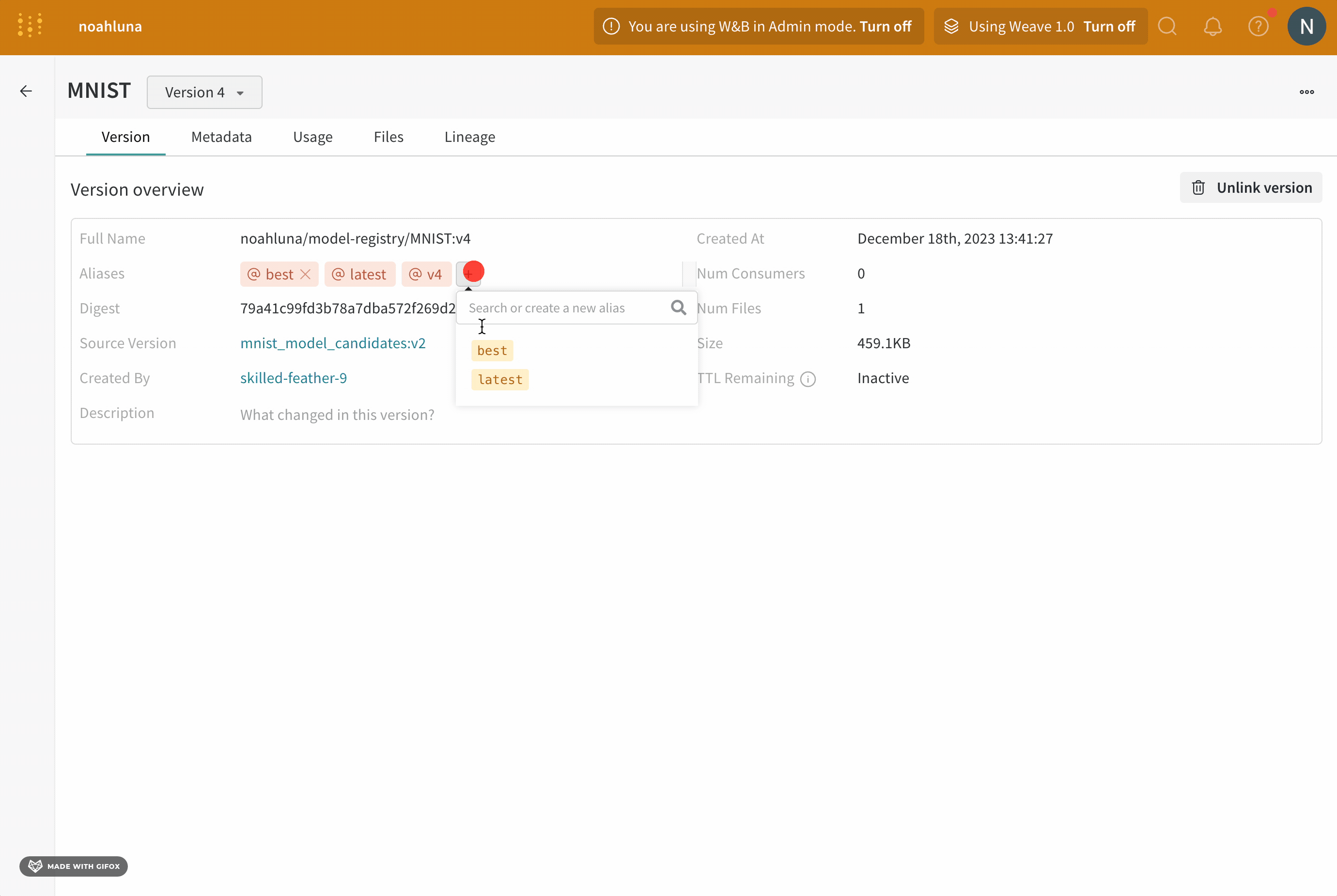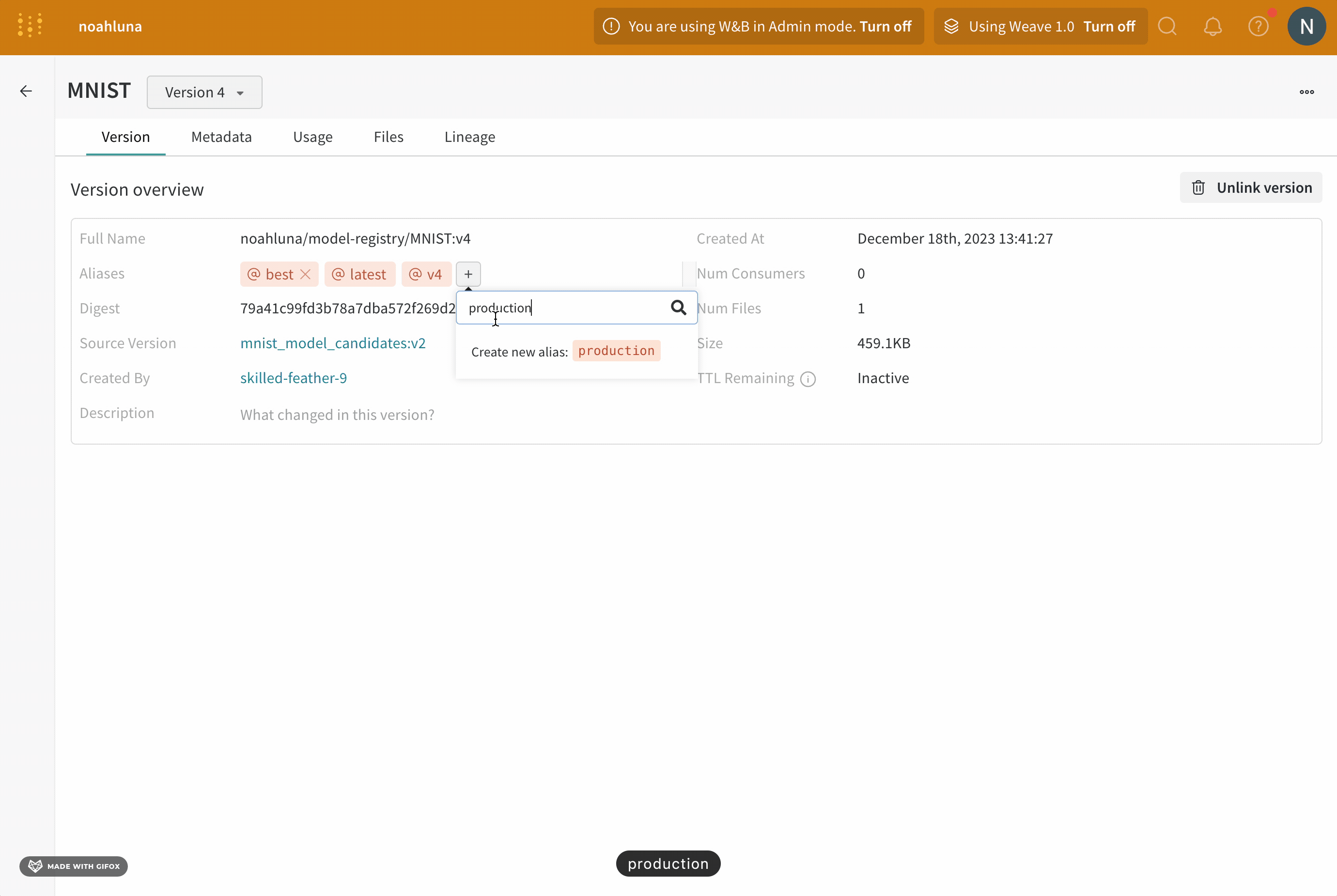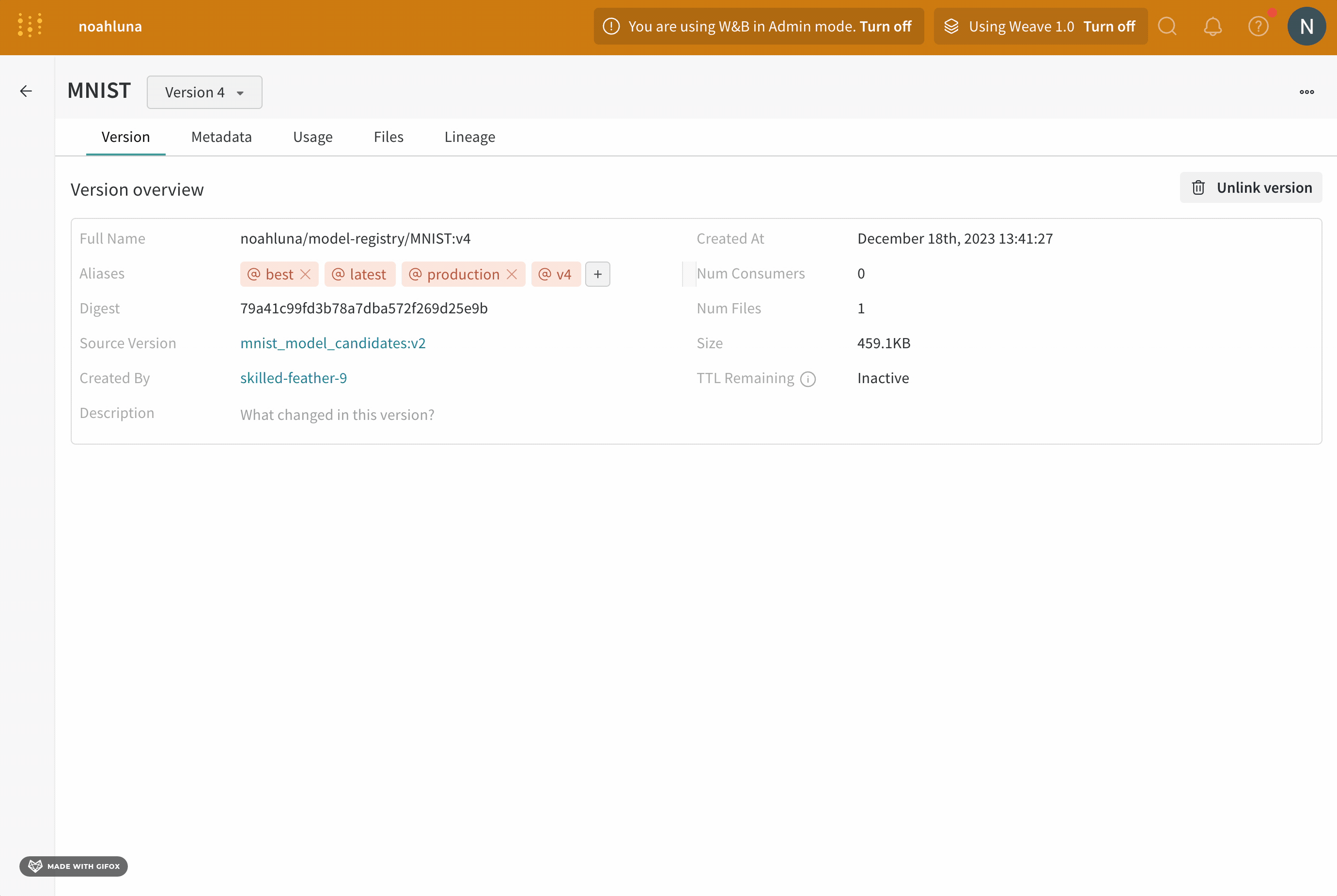
例えば、モデルのパフォーマンスを評価した後、そのモデルがプロダクションの準備が整ったと確信したとします。モデルバージョンを昇格させるために、特定のモデルバージョンに production エイリアスを追加します。
production エイリアスは、モデルをプロダクション対応としてマークするために使用される最も一般的なエイリアスの 1 つです。
W&B アプリ UI を使用してインタラクティブに、または Python SDK を使用してプログラムでモデルバージョンにエイリアスを追加できます。次のステップは、W&B Model Registry App を使用してエイリアスを追加する方法を示しています:
https://wandb.ai/registry/model の Model Registry App に移動します。登録されているモデルの名前の横にある View details をクリックします。
Versions セクション内で、プロモーションしたいモデルバージョンの名前の横にある View ボタンをクリックします。Aliases フィールドの隣にあるプラスアイコン (+ ) をクリックします。表示されるフィールドに production と入力します。
キーボードの Enter キーを押します。
2 - モデルレジストリの用語と概念
モデルレジストリの用語と概念
以下の用語は、W&B モデルレジストリの主要な構成要素を説明します: model version model artifact registered model
Model version
モデルバージョンは、単一のモデルチェックポイントを表します。モデルバージョンは、実験内のモデルとそのファイルのある時点でのスナップショットです。
モデルバージョンは、訓練されたモデルを記述するデータとメタデータの不変なディレクトリーです。W&B は、後でモデルのアーキテクチャーと学習されたパラメータを保存(および復元)できるように、ファイルをモデルバージョンに追加することを推奨しています。
モデルバージョンは、1つだけの model artifact に属します。モデルバージョンは、ゼロまたは複数の registered models に属する場合があります。モデルバージョンは、model artifact にログされる順序で格納されます。同じ model artifact にログされたモデルの内容が以前のモデルバージョンと異なる場合、W&B は自動的に新しいモデルバージョンを作成します。
モデリングライブラリによって提供されるシリアライズプロセスから生成されたファイルをモデルバージョン内に保存します(例:PyTorch と Keras )。
Model alias
モデルエイリアスは、登録されたモデル内でモデルバージョンを一意に識別または参照するための可変文字列です。登録されたモデルのバージョンにだけエイリアスを割り当てることができます。これは、エイリアスがプログラム的に使用されたとき、一意のバージョンを指す必要があるためです。エイリアスは、モデルの状態(チャンピオン、候補、プロダクション)をキャプチャするためにも使用されます。
“best”、“latest”、“production”、“staging” のようなエイリアスを使用して、特定の目的を持つモデルバージョンにマークを付けることは一般的です。
たとえば、モデルを作成し、それに “best” エイリアスを割り当てたとします。その特定のモデルを run.use_model で参照できます。
import wandb
run = wandb. init()
name = f " { entity/ project/ model_artifact_name} : { alias} "
run. use_model(name= name)
モデルタグは、1つ以上の登録されたモデルに属するキーワードまたはラベルです。
モデルタグを使用して、登録されたモデルをカテゴリに整理し、モデルレジストリの検索バーでそれらのカテゴリを検索します。モデルタグは Registered Model Card の上部に表示されます。ML タスク、所有チーム、または優先順位に基づいて登録モデルをグループ化するために使用することもできます。同じモデルタグを複数の登録されたモデルに追加してグループ化を可能にします。
登録されたモデルに適用されるラベルで、グループ化と発見性のために使用されるモデルタグは、
model aliases とは異なります。モデルエイリアスは、一意の識別子またはニックネームで、プログラム的にモデルバージョンを取得するために使用します。モデルレジストリでタスクを整理するためのタグの使用について詳しくは、
Organize models を参照してください。
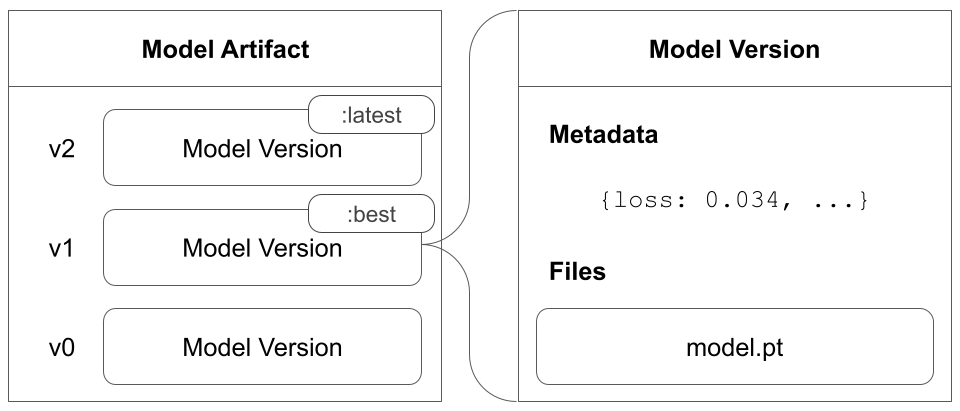
Model artifact
モデルアーティファクトは、ログされた model versions のコレクションです。モデルバージョンは、model artifact にログされた順序で保存されます。
モデルアーティファクトには1つ以上のモデルバージョンが含まれる場合があります。モデルバージョンがログされていない場合、モデルアーティファクトは空です。
たとえば、モデルアーティファクトを作成するとします。モデルのトレーニング中に、定期的にチェックポイントでモデルを保存します。各チェックポイントはその独自の model version に対応しています。トレーニングスクリプトの開始時に作成した同じモデルアーティファクトに、モデルトレーニング中とチェックポイント保存中に作成されたすべてのモデルバージョンが保存されます。
以下の画像は、3つのモデルバージョン v0、v1、v2 を含むモデルアーティファクトを示しています。
モデルアーティファクトの例はこちら をご覧ください。
Registered model
登録モデルは、モデルバージョンへのポインタ(リンク)のコレクションです。登録モデルを、同じ ML タスク用の候補モデルの「ブックマーク」フォルダーとして考えることができます。登録モデルの各「ブックマーク」は、model artifact に属する model version へのポインタです。model tags を使用して登録モデルをグループ化することができます。
登録モデルは、単一のモデリングユースケースやタスクに対する候補モデルを表すことがよくあります。たとえば、使用するモデルに基づいて異なる画像分類タスクの登録モデルを作成するかもしれません:ImageClassifier-ResNet50、ImageClassifier-VGG16、DogBreedClassifier-MobileNetV2 など。モデルバージョンは、登録モデルにリンクされた順にバージョン番号が割り当てられます。
登録モデルの例はこちら をご覧ください。
3 - モデルを追跡する
W&B Python SDK を使用して、モデル、モデルの依存関係、およびそのモデルに関連するその他の情報を追跡します。
モデル、モデルの依存関係、およびそのモデルに関連するその他の情報を W&B Python SDK を使用して追跡します。
内部的には、W&B は モデルアーティファクト のリネージを作成し、W&B アプリ UI で表示したり、W&B Python SDK を使用してプログラム的に確認することができます。詳細は モデルリネージマップの作成 を参照してください。
モデルをログする方法
run.log_model API を使用してモデルをログします。モデルファイルが保存されているパスを path パラメータに提供してください。このパスはローカルファイル、ディレクトリー、または s3://bucket/path のような外部バケットへのリファレンス URI のいずれかにすることができます。
オプションでモデルアーティファクトの名前を name パラメータに指定できます。name が指定されていない場合、W&B は入力パスのベース名を実行 ID を前に付けたものとして使用します。
以下のコードスニペットをコピーして貼り付けてください。<> で囲まれた値をあなた自身のものに置き換えてください。
import wandb
# W&B run を初期化
run = wandb. init(project= "<project>" , entity= "<entity>" )
# モデルをログする
run. log_model(path= "<path-to-model>" , name= "<name>" )
例: Keras モデルを W&B にログする
以下のコード例は、畳み込みニューラルネットワーク (CNN) モデルを W&B にログする方法を示します。
import os
import wandb
from tensorflow import keras
from tensorflow.keras import layers
config = {"optimizer" : "adam" , "loss" : "categorical_crossentropy" }
# W&B run を初期化
run = wandb. init(entity= "charlie" , project= "mnist-project" , config= config)
# トレーニングアルゴリズム
loss = run. config["loss" ]
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
num_classes = 10
input_shape = (28 , 28 , 1 )
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# モデルを保存
model_filename = "model.h5"
local_filepath = "./"
full_path = os. path. join(local_filepath, model_filename)
model. save(filepath= full_path)
# モデルをログする
run. log_model(path= full_path, name= "MNIST" )
# W&B に対して明示的に run の終了を通知します。
run. finish()
4 - 登録済みモデルを作成する
モデル作成のタスクのために、すべての候補モデルを保持する Registered Model を作成します。
registered model を作成し、モデリングタスクのすべての候補モデルを保持します。モデルレジストリ内でインタラクティブに、または Python SDK を使用してプログラム的に registered model を作成できます。
プログラムで registered model を作成する
W&B Python SDK を使用してモデルを登録します。registered model が存在しない場合、W&B は自動的に registered model を作成します。
<> で囲まれた他の値をあなた自身のもので置き換えてください:
import wandb
run = wandb. init(entity= "<entity>" , project= "<project>" )
run. link_model(path= "<path-to-model>" , registered_model_name= "<registered-model-name>" )
run. finish()
registered_model_name に指定した名前は Model Registry App に表示される名前です。
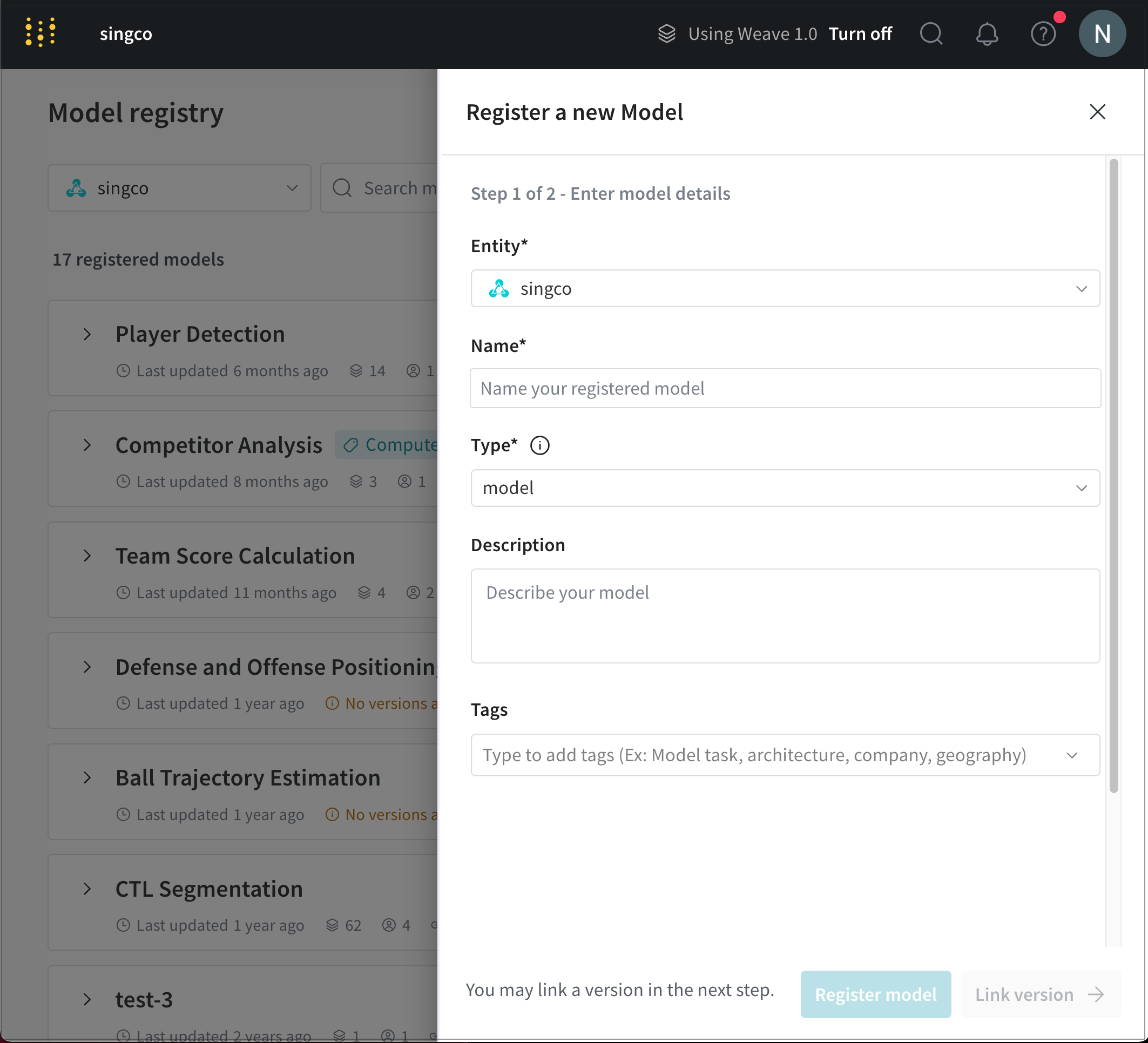
インタラクティブに registered model を作成する
Model Registry App でインタラクティブに registered model を作成します。
Model Registry App に移動します: https://wandb.ai/registry/model 。
Model Registry ページの右上にある New registered model ボタンをクリックします。
表示されたパネルから、registered model が属するエンティティを Owning Entity ドロップダウンから選択します。
Name フィールドにモデルの名前を入力します。Type ドロップダウンから、registered model とリンクするアーティファクトのタイプを選択します。(オプション) Description フィールドにモデルについての説明を追加します。
(オプション) Tags フィールドに1つ以上のタグを追加します。
Register model をクリックします。
モデルをモデルレジストリに手動でリンクすることは、一度だけのモデルに便利です。しかし、プログラムでモデルバージョンをモデルレジストリにリンクする こともよくあります。
例えば、毎晩のジョブがあるとします。毎晩作成されるモデルを手動でリンクするのは面倒です。代わりに、モデルを評価し、そのモデルがパフォーマンスを改善した場合にそのモデルを W&B Python SDK を使用してモデルレジストリにリンクするスクリプトを作成することができます。
5 - モデルバージョンをリンクする
モデル バージョンを登録されたモデルに、W&B アプリまたは Python SDK を使ってプログラム的にリンクします。
モデルのバージョンを W&B App または Python SDK を使用してプログラムで登録済みのモデルにリンクします。
プログラムでモデルをリンクする
link_modelW&B モデルレジストリ にリンクします。
<>で囲まれた値を自分のものに置き換えることを忘れないでください:
import wandb
run = wandb. init(entity= "<entity>" , project= "<project>" )
run. link_model(path= "<path-to-model>" , registered_model_name= "<registered-model-name>" )
run. finish()
指定した registered-model-name パラメータの名前が既に存在しない場合、W&B は登録済みのモデルを自動的に作成します。
例えば、既に “Fine-Tuned-Review-Autocompletion” という名前の登録済みモデル(registered-model-name="Fine-Tuned-Review-Autocompletion")がモデルレジストリにあり、それにいくつかのモデルバージョンがリンクされているとします: v0、v1、v2。新しいモデルをプログラムでリンクし、同じ登録済みモデル名を使用した場合(registered-model-name="Fine-Tuned-Review-Autocompletion")、W&B はこのモデルを既存の登録済みモデルにリンクし、モデルバージョン v3 を割り当てます。この名前の登録済みモデルが存在しない場合、新しい登録済みモデルが作成され、モデルバージョン v0 を持ちます。
“Fine-Tuned-Review-Autocompletion” 登録済みモデルの一例をここでご覧ください .
インタラクティブにモデルをリンクする
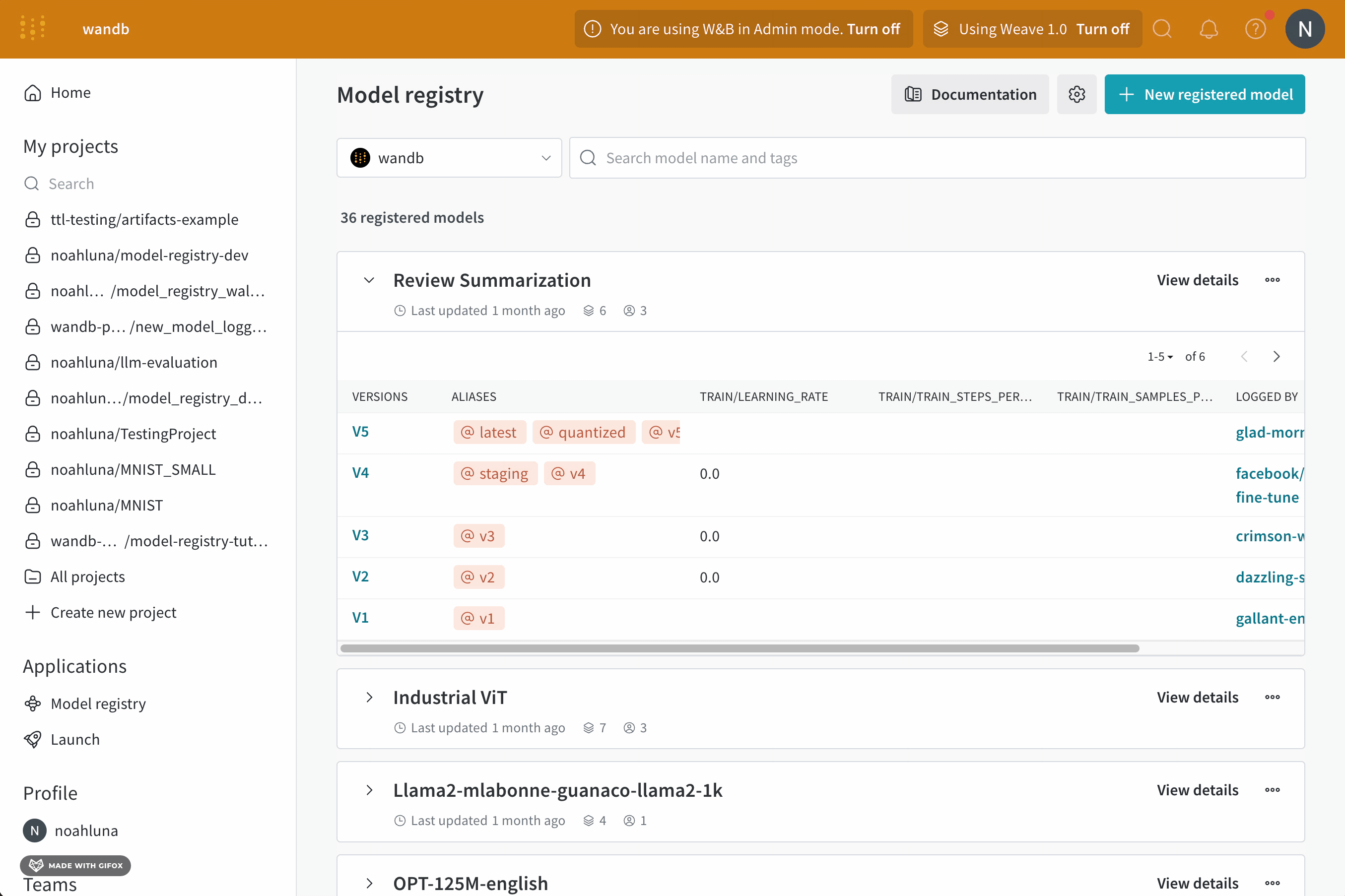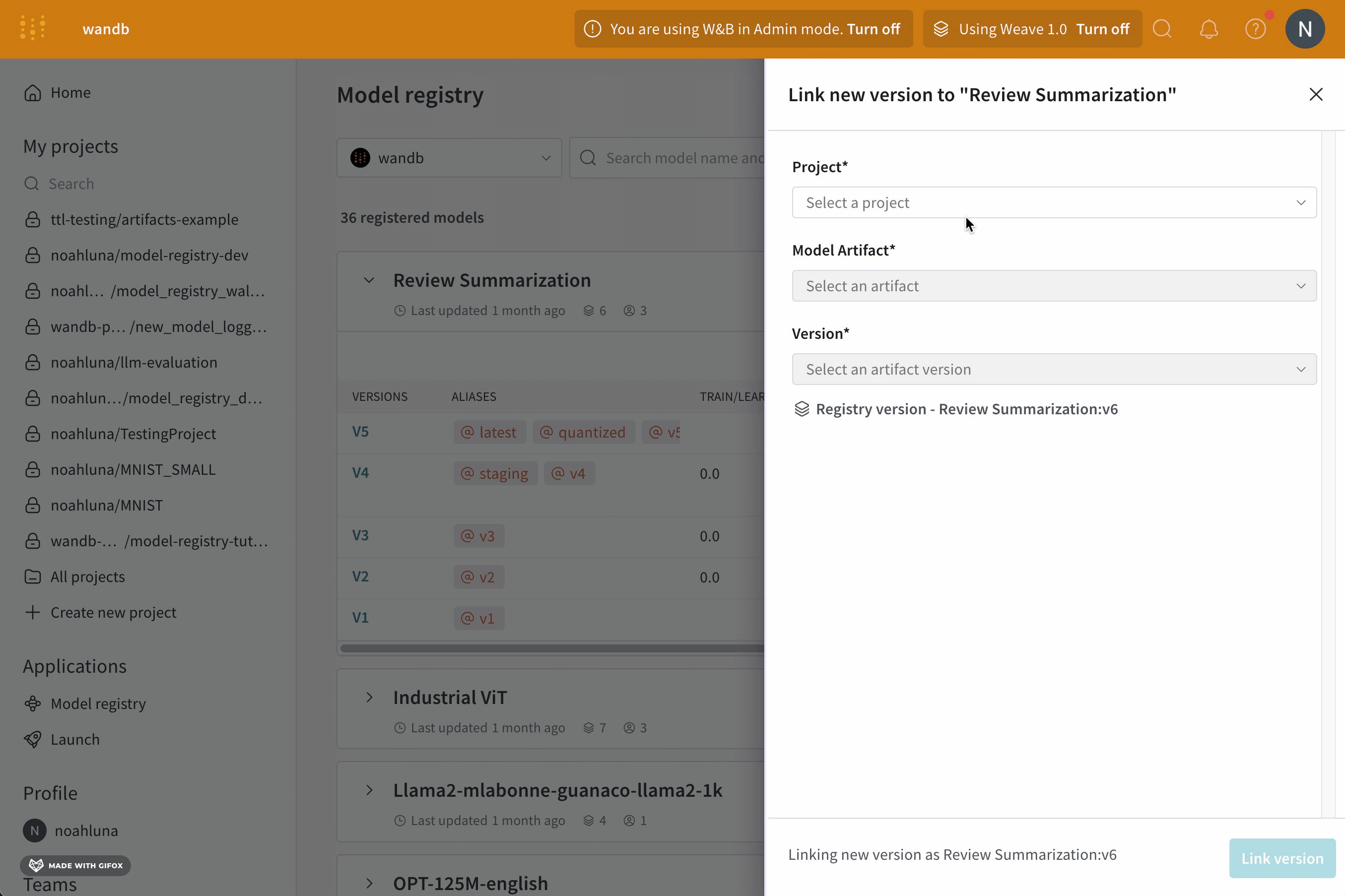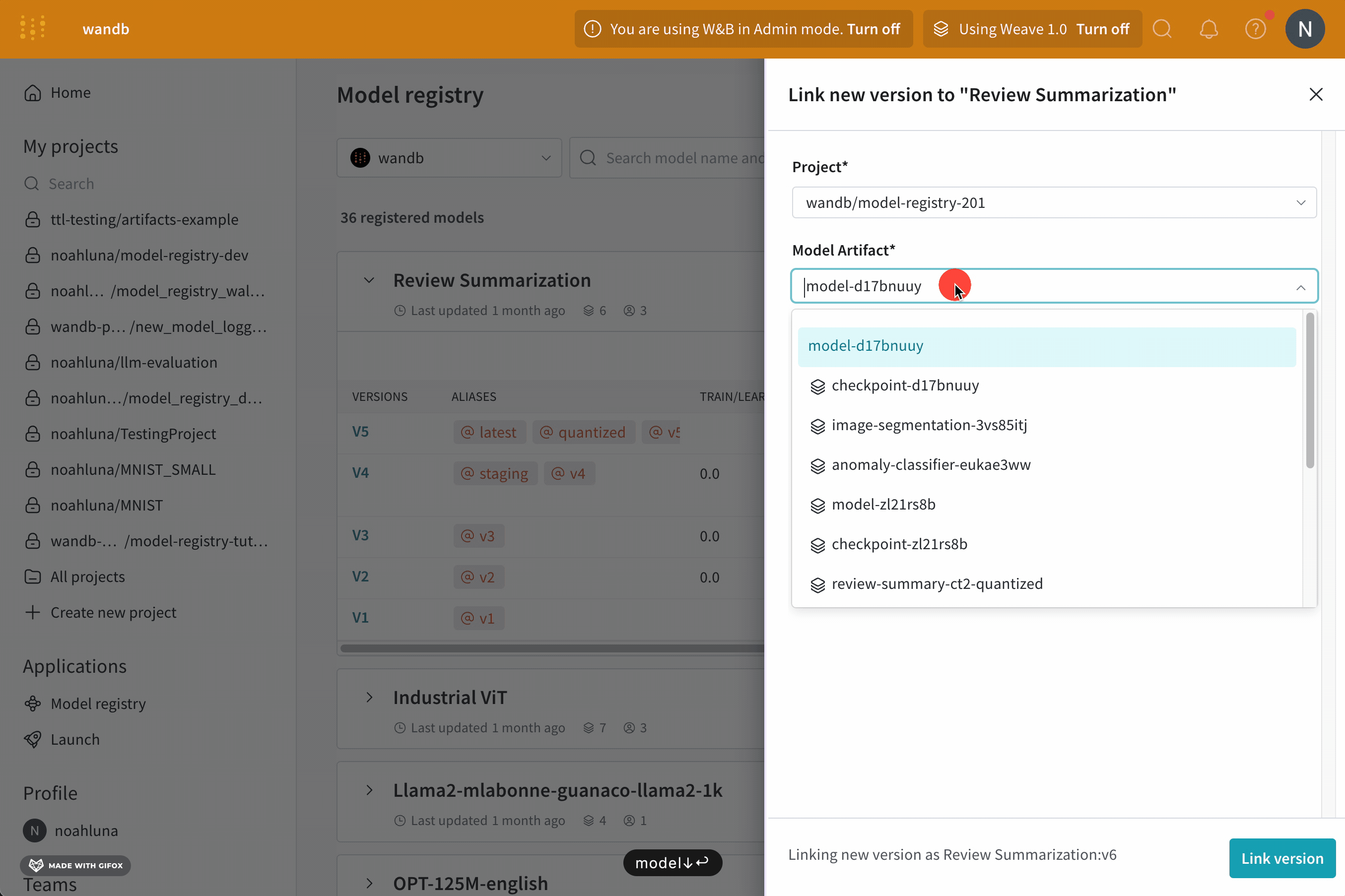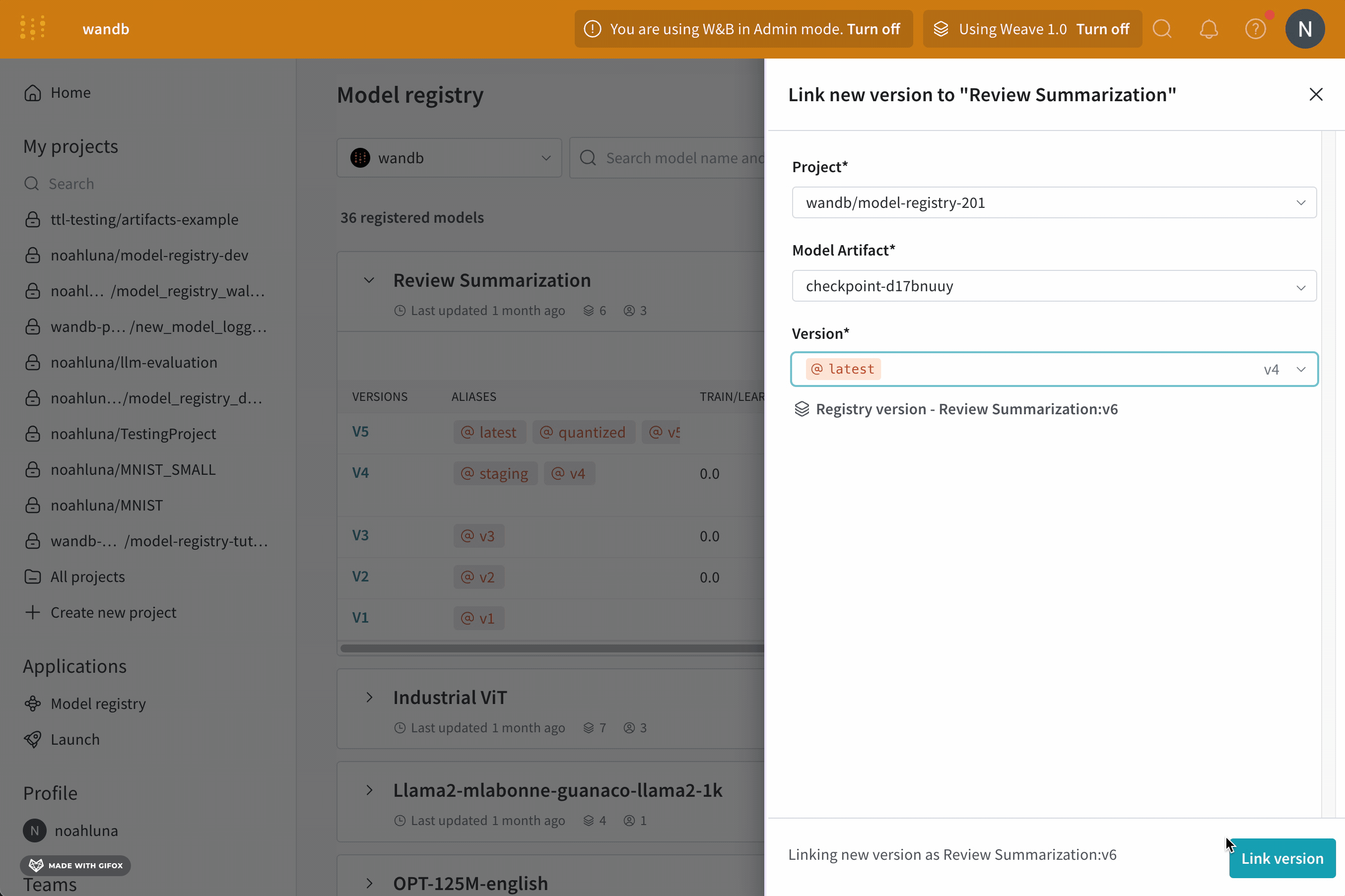
インタラクティブにモデルレジストリまたはアーティファクトブラウザでモデルをリンクします。
Model Registry
Artifact browser
https://wandb.ai/registry/model のモデルレジストリアプリに移動します。新しいモデルをリンクしたい登録済みモデルの名前の横にマウスをホバーします。
View details の横のミートボールメニューアイコン(三つの水平な点)を選択します。ドロップダウンメニューから Link new version を選択します。
Project ドロップダウンからモデルを含むプロジェクトの名前を選択します。Model Artifact ドロップダウンからモデルアーティファクトの名前を選択します。Version ドロップダウンから登録済みモデルにリンクしたいモデルバージョンを選択します。
W&B App でプロジェクトのアーティファクトブラウザに移動します: https://wandb.ai/<entity>/<project>/artifacts
左側のサイドバーで Artifacts アイコンを選択します。
リストにあなたのモデルを表示したいプロジェクトを表示します。
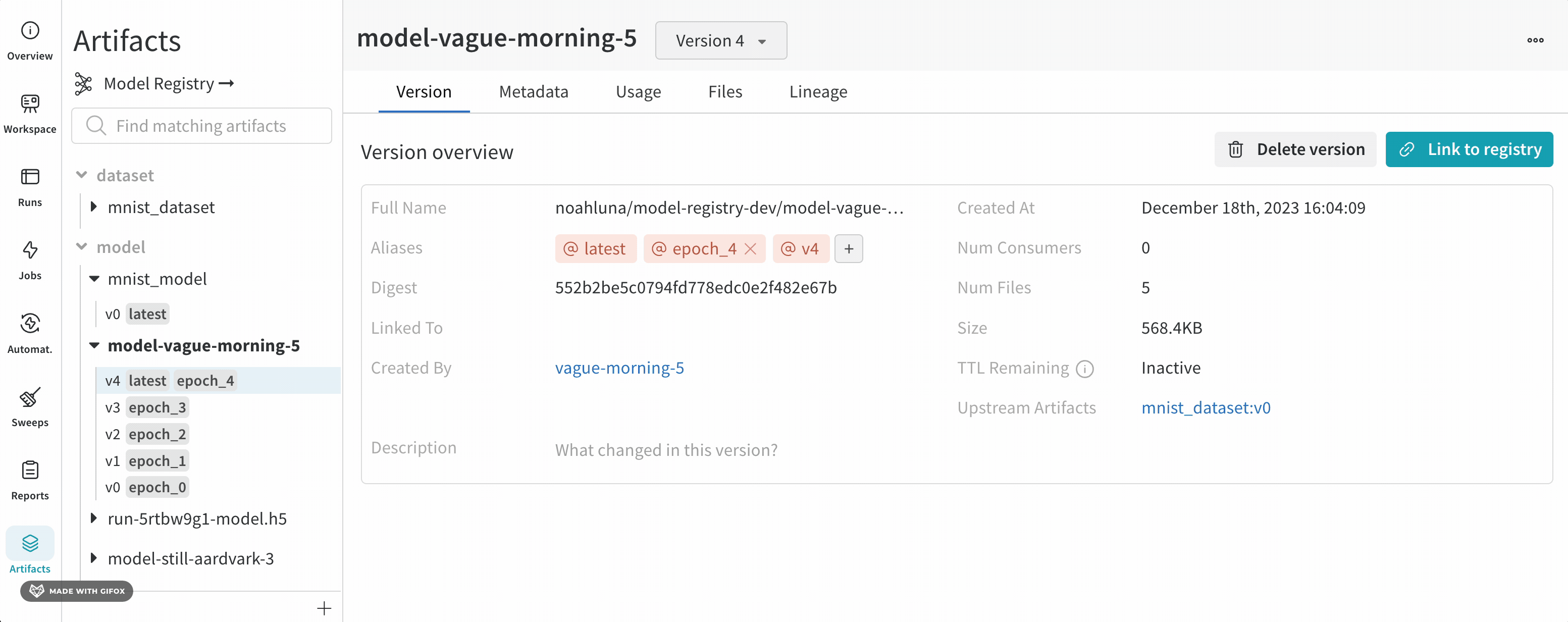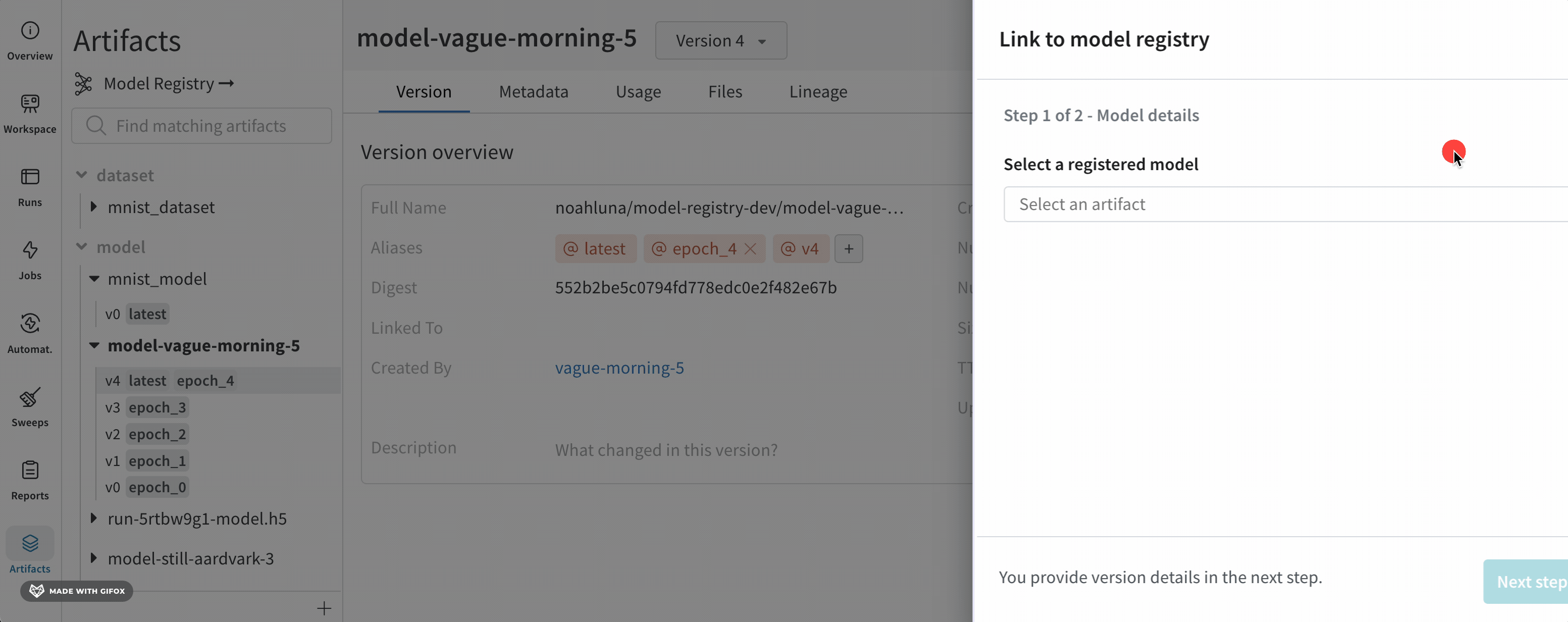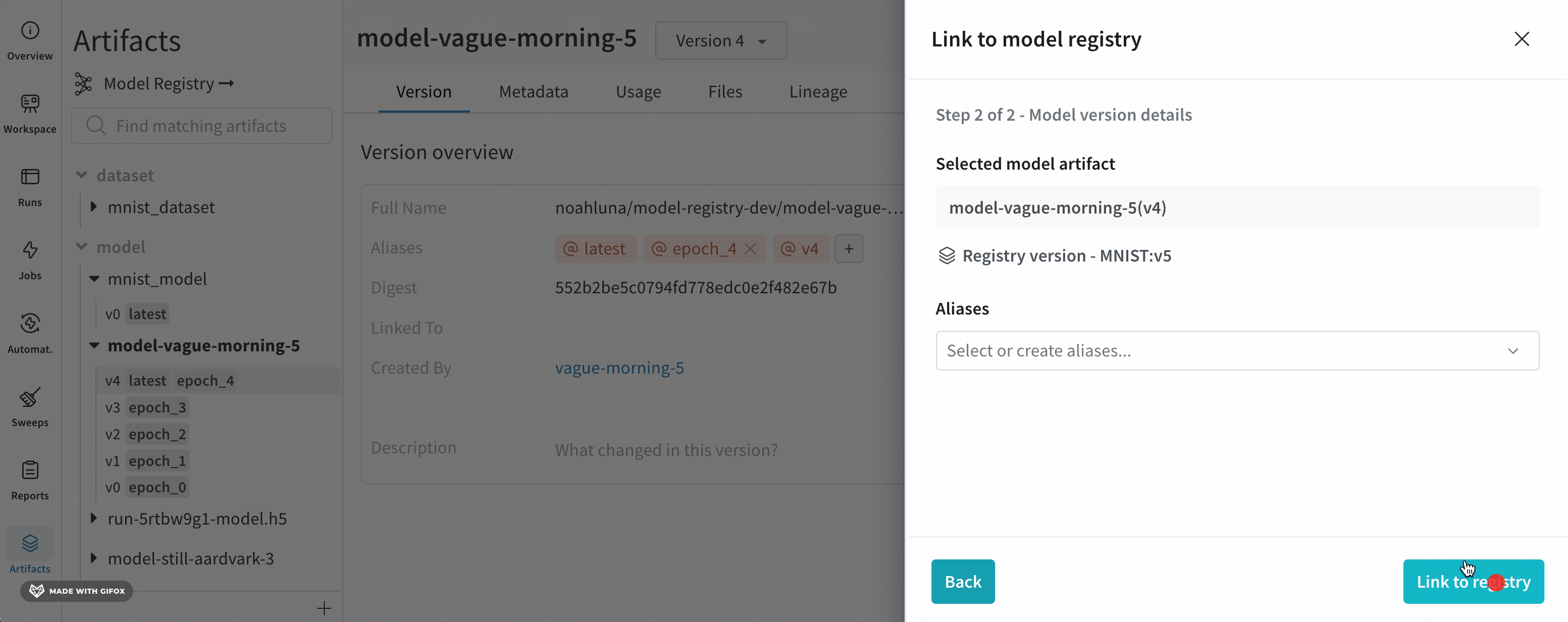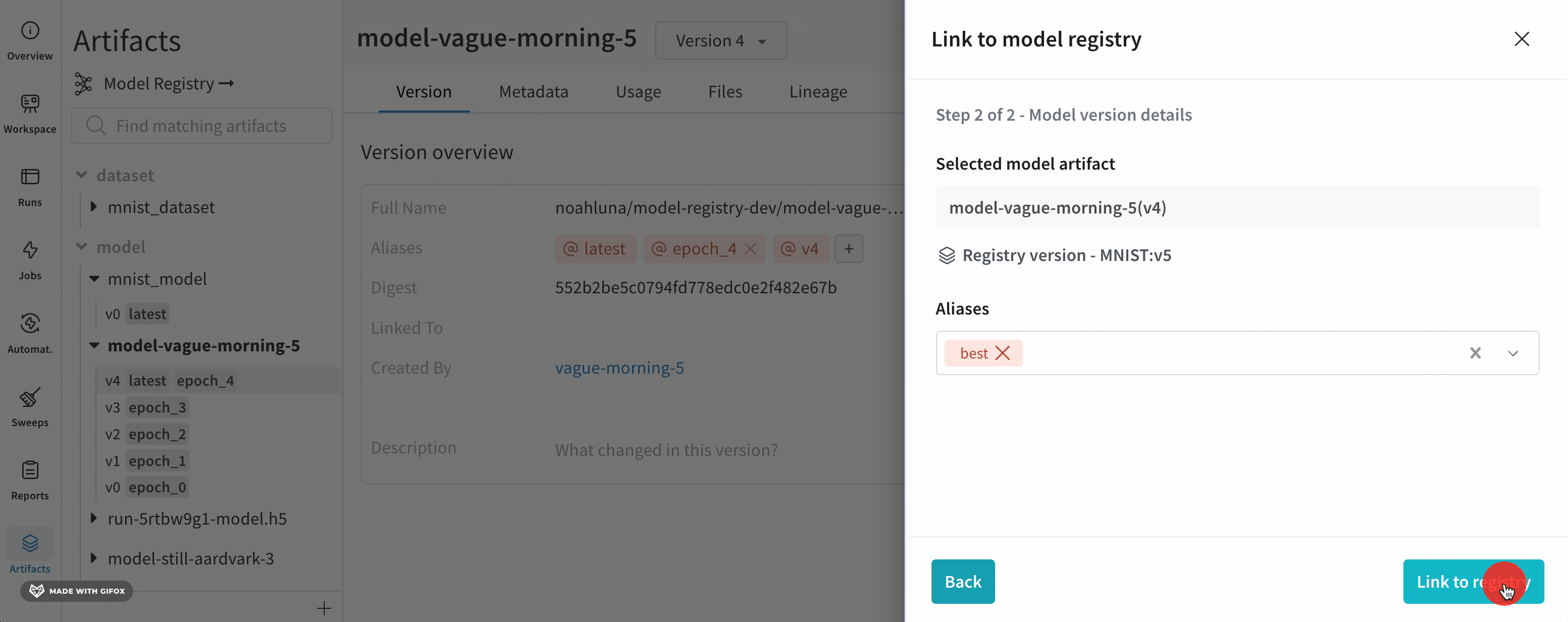
モデルのバージョンをクリックして、モデルレジストリにリンクします。
画面右側に表示されるモーダルから、Select a register model メニュードロップダウンから登録済みモデルを選択します。
Next step をクリックします。(オプション)Aliases ドロップダウンからエイリアスを選択します。
Link to registry をクリックします。
リンクされたモデルのソースを表示する
リンクされたモデルのソースを表示する方法は2つあります: モデルがログされているプロジェクト内のアーティファクトブラウザと W&B モデルレジストリです。
モデルレジストリ内の特定のモデルバージョンを、(そのモデルがログされているプロジェクト内に位置する)ソースモデルアーティファクトと接続するポインタがあります。ソースモデルアーティファクトにもモデルレジストリへのポインタがあります。
Model Registry
Artifact browser
https://wandb.ai/registry/model でモデルレジストリに移動します。
登録済みモデルの名前の横で View details を選択します。
Versions セクション内で調査したいモデルバージョンの横にある View を選択します。右パネル内の Version タブをクリックします。
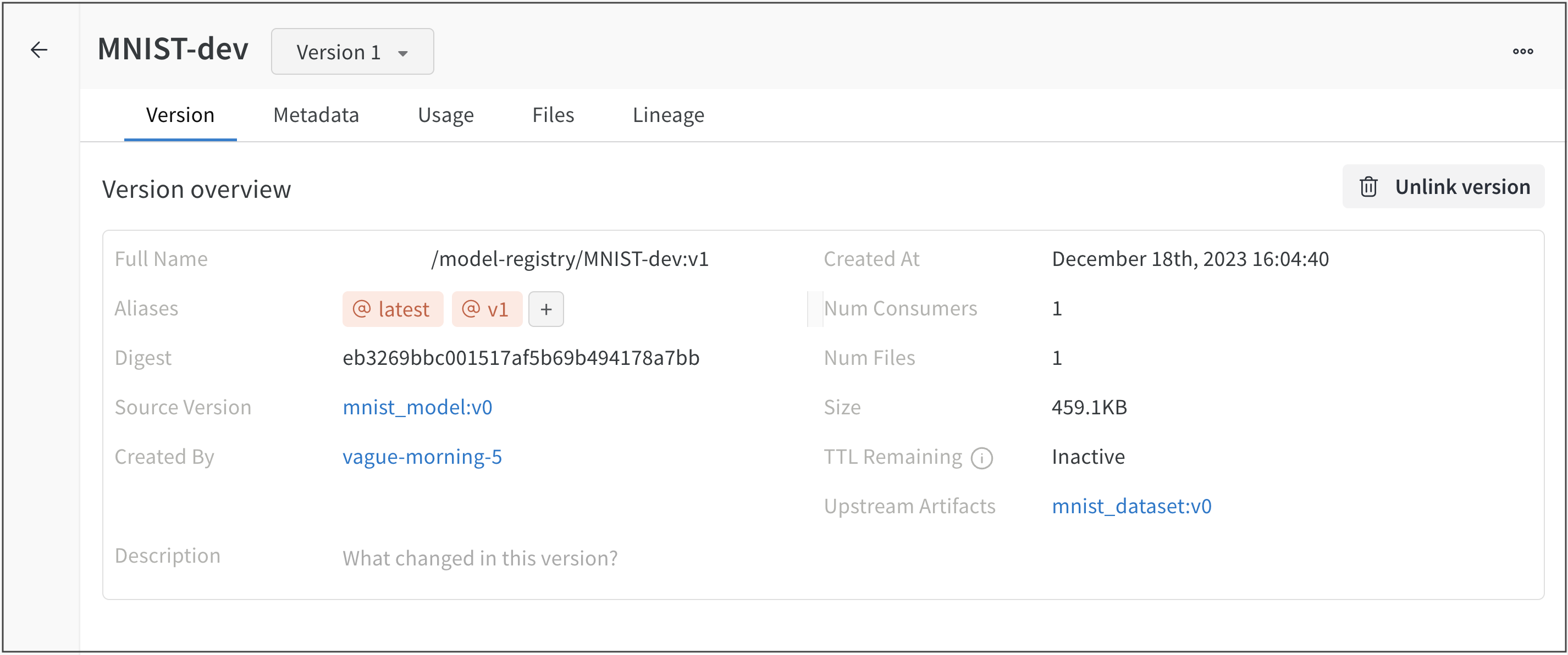
Version overview セクション内に Source Version フィールドを含む行があります。Source Version フィールドはモデルの名前とそのバージョンを示しています。
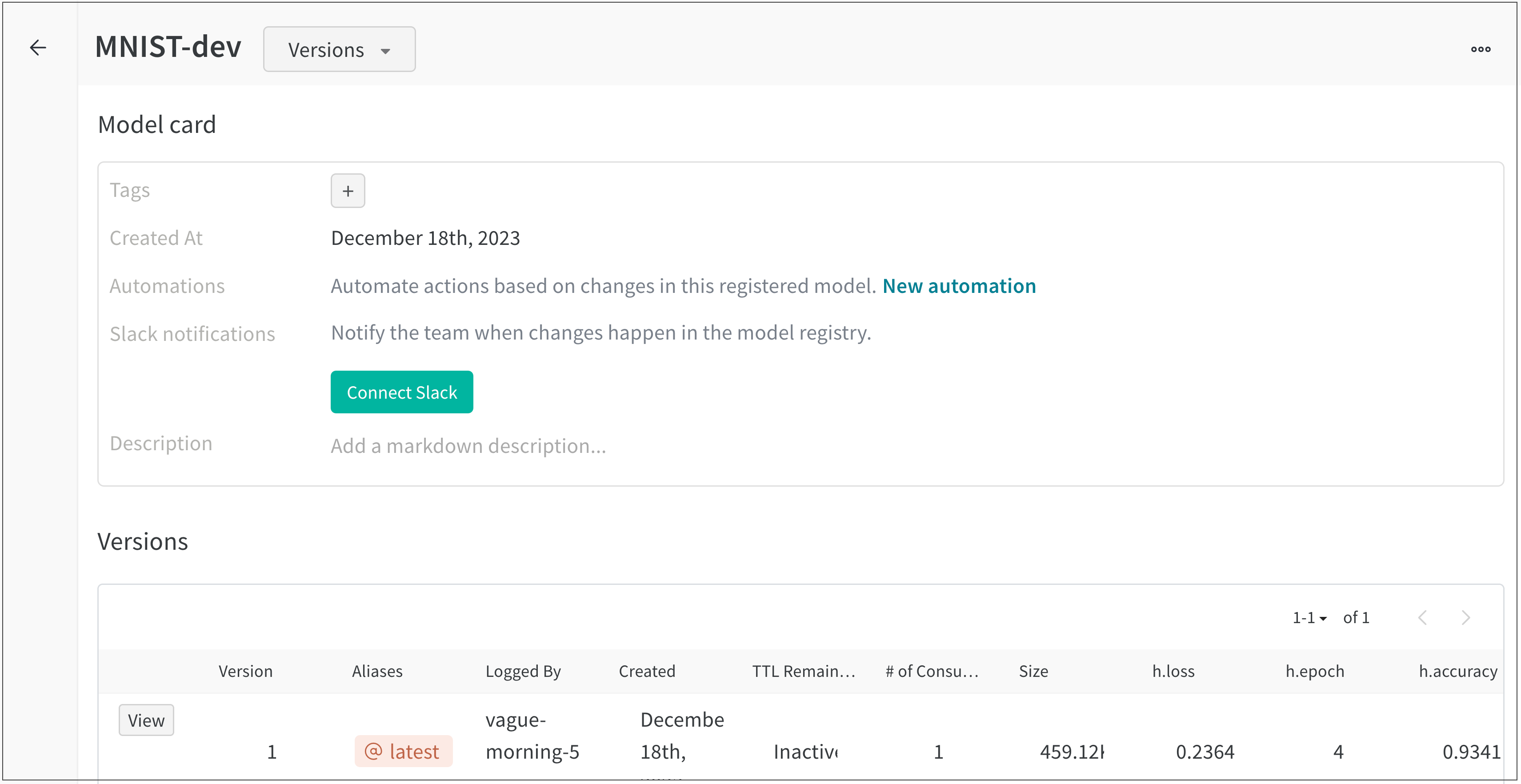
例えば、次の画像は v0 モデルバージョンである mnist_model (Source version フィールド mnist_model:v0 を参照)を登録済みモデル MNIST-dev にリンクしていることを示しています。
W&B App でプロジェクトのアーティファクトブラウザに移動します: https://wandb.ai/<entity>/<project>/artifacts
左側のサイドバーで Artifacts アイコンを選択します。
アーティファクトパネルから model ドロップダウンメニューを展開します。
モデルレジストリにリンクされたモデルの名前とバージョンを選択します。
右パネル内の Version タブをクリックします。
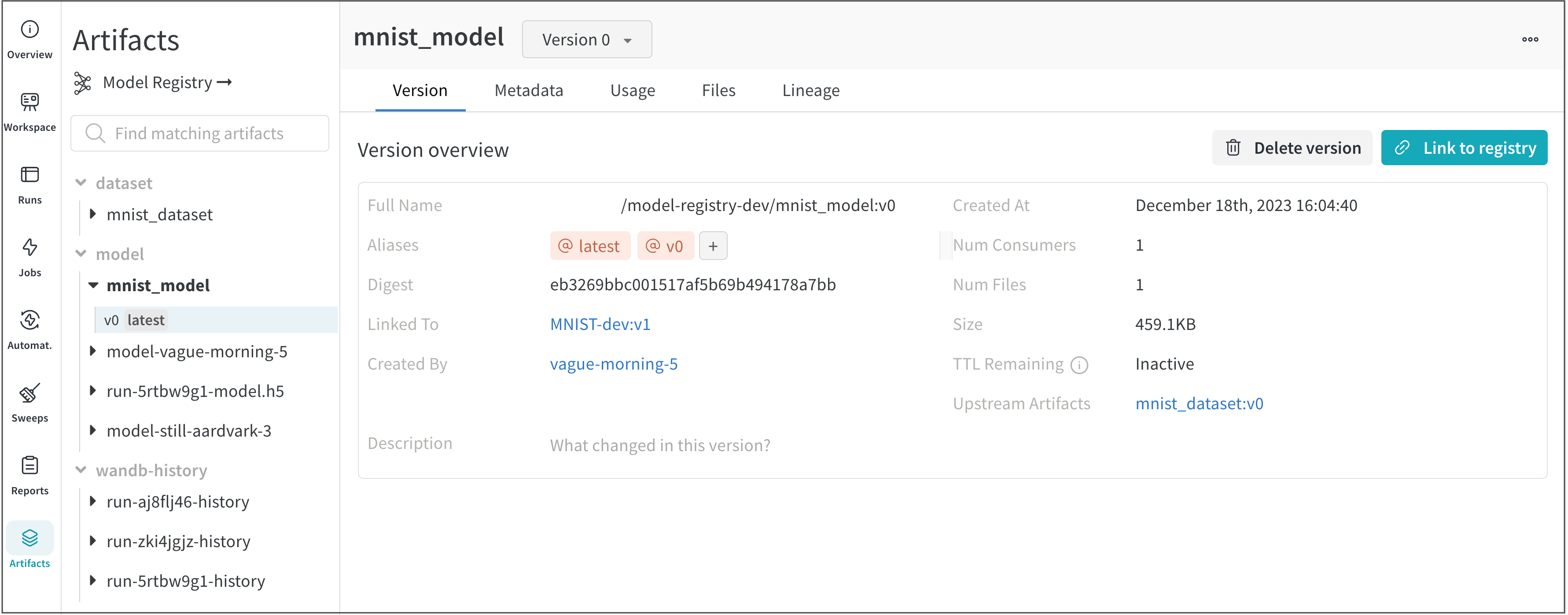
Version overview セクション内に Linked To フィールドを含む行があります。Linked To フィールドは、登録済みモデルの名前とそれに属するバージョンを示しています(registered-model-name:version)。
例えば、次の画像では、MNIST-dev という登録済みモデルがあります(Linked To フィールドを参照)。バージョン v0 のモデルバージョン mnist_model(mnist_model:v0)が MNIST-dev 登録済みモデルを指しています。
6 - モデルを整理する
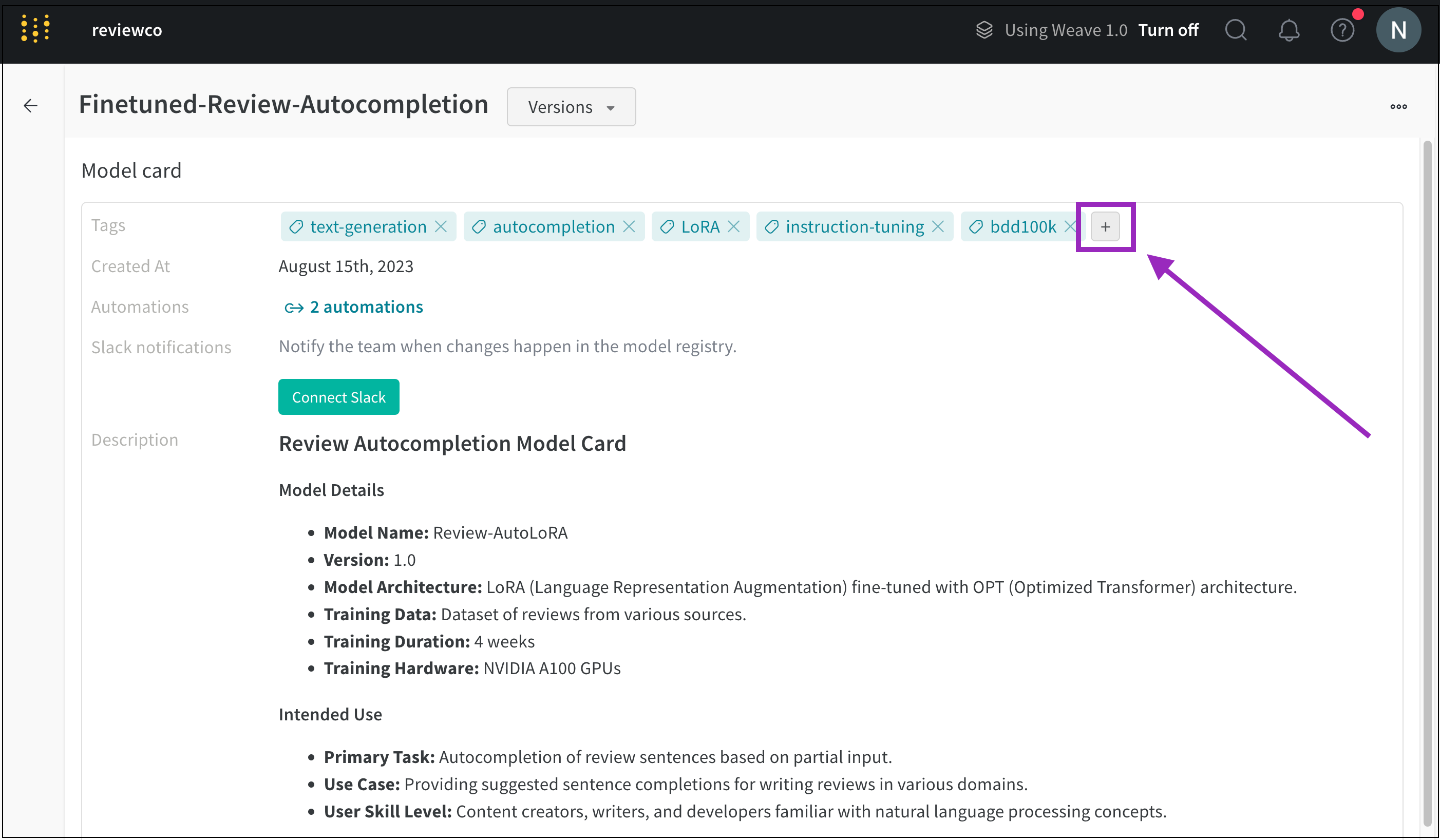
モデルタグを使用して登録済みのモデルをカテゴリーに整理し、それらのカテゴリーを検索します。
https://wandb.ai/registry/model で W&B モデルレジストリアプリに移動します。
モデルタグを追加したい登録済みモデルの名前の横にある View details を選択します。
Model card セクションまでスクロールします。
Tags フィールドの横にあるプラスボタン (+ ) をクリックします。
タグの名前を入力するか、既存のモデルタグを検索します。
例えば、次の画像は FineTuned-Review-Autocompletion という登録済みモデルに複数のモデルタグが追加されている様子を示しています。
7 - モデルリネージ マップを作成する
このページでは、従来の W&B Model Registry でのリネージグラフの作成について説明します。W&B Registry でのリネージグラフについて学ぶには、リネージマップの作成と表示 を参照してください。
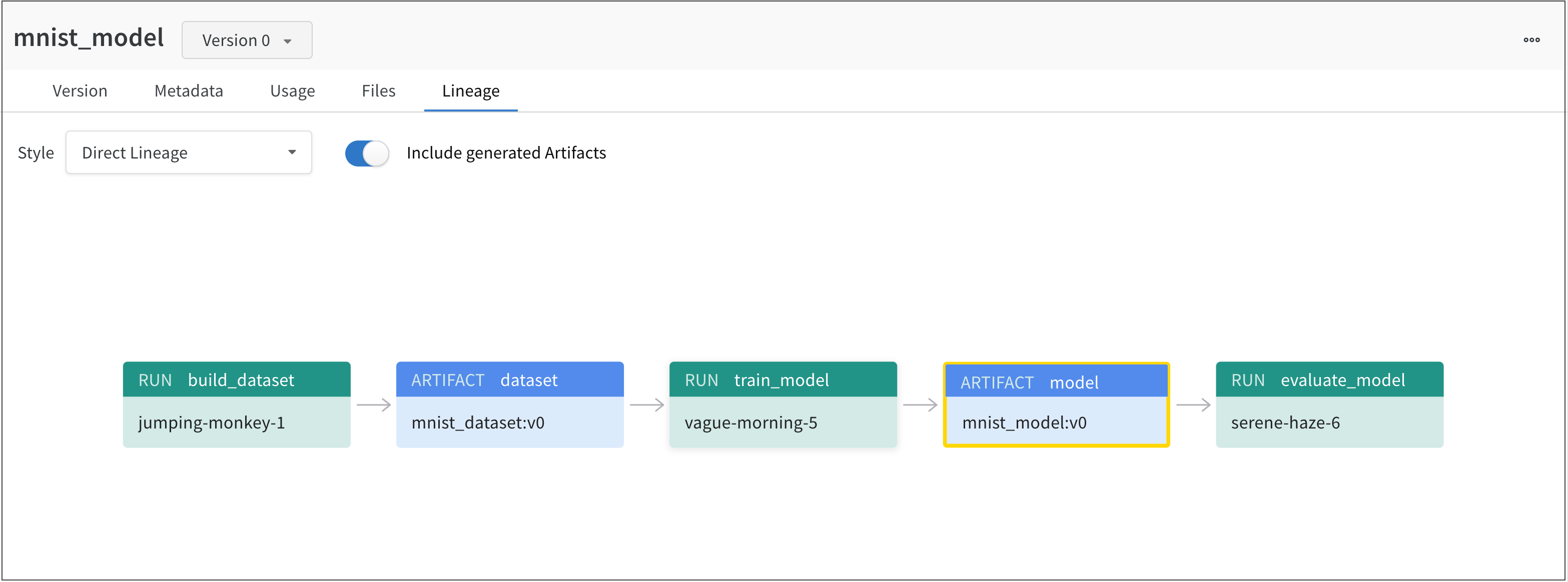
モデルアーティファクトを W&B にログする際の便利な機能の一つにリネージグラフがあります。リネージグラフは、run によってログされたアーティファクトと特定の run で使用されたアーティファクトを表示します。
つまり、モデルアーティファクトをログする際には、少なくともモデルアーティファクトを使用または生成した W&B run を表示するためのアクセスが可能です。依存関係を追跡する 場合、モデルアーティファクトで使用された入力も見ることができます。
例えば、以下の画像では、ML 実験全体で作成および使用されたアーティファクトが示されています。
画像は左から右に向かって次のように示しています。
jumping-monkey-1 W&B run によって mnist_dataset:v0 のデータセットアーティファクトが作成されました。vague-morning-5 W&B run は mnist_dataset:v0 データセットアーティファクトを使用してモデルをトレーニングしました。この W&B run の出力は mnist_model:v0 というモデルアーティファクトでした。serene-haze-6 という run は mnist_model:v0 のモデルアーティファクトを使用してモデルを評価しました。
アーティファクトの依存関係を追跡
データセットアーティファクトを W&B run の入力として宣言することで、use_artifact API を使用して依存関係を追跡できます。
以下のコードスニペットでは、use_artifact API の使用方法を示します。
# Run を初期化
run = wandb. init(project= project, entity= entity)
# アーティファクトを取得し、依存関係としてマーク
artifact = run. use_artifact(artifact_or_name= "name" , aliases= "<alias>" )
アーティファクトを取得した後、そのアーティファクトを使用して(例えば)、モデルのパフォーマンスを評価できます。
例: モデルを訓練し、データセットをモデルの入力として追跡
job_type = "train_model"
config = {
"optimizer" : "adam" ,
"batch_size" : 128 ,
"epochs" : 5 ,
"validation_split" : 0.1 ,
}
run = wandb. init(project= project, job_type= job_type, config= config)
version = "latest"
name = " {} : {} " . format(" {} _dataset" . format(model_use_case_id), version)
artifact = run. use_artifact(name)
train_table = artifact. get("train_table" )
x_train = train_table. get_column("x_train" , convert_to= "numpy" )
y_train = train_table. get_column("y_train" , convert_to= "numpy" )
# 設定辞書から変数に値を保存して簡単にアクセス
num_classes = 10
input_shape = (28 , 28 , 1 )
loss = "categorical_crossentropy"
optimizer = run. config["optimizer" ]
metrics = ["accuracy" ]
batch_size = run. config["batch_size" ]
epochs = run. config["epochs" ]
validation_split = run. config["validation_split" ]
# モデルアーキテクチャーの作成
model = keras. Sequential(
[
layers. Input(shape= input_shape),
layers. Conv2D(32 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Conv2D(64 , kernel_size= (3 , 3 ), activation= "relu" ),
layers. MaxPooling2D(pool_size= (2 , 2 )),
layers. Flatten(),
layers. Dropout(0.5 ),
layers. Dense(num_classes, activation= "softmax" ),
]
)
model. compile(loss= loss, optimizer= optimizer, metrics= metrics)
# トレーニングデータのラベルを生成
y_train = keras. utils. to_categorical(y_train, num_classes)
# トレーニングセットとテストセットの作成
x_t, x_v, y_t, y_v = train_test_split(x_train, y_train, test_size= 0.33 )
# モデルのトレーニング
model. fit(
x= x_t,
y= y_t,
batch_size= batch_size,
epochs= epochs,
validation_data= (x_v, y_v),
callbacks= [WandbCallback(log_weights= True , log_evaluation= True )],
)
# モデルをローカルに保存
path = "model.h5"
model. save(path)
path = "./model.h5"
registered_model_name = "MNIST-dev"
name = "mnist_model"
run. link_model(path= path, registered_model_name= registered_model_name, name= name)
run. finish()
8 - モデルバージョンをダウンロードする
W&B Python SDK で モデル をダウンロードする方法
W&B Python SDK を使用して、Model Registry にリンクしたモデルアーティファクトをダウンロードします。
モデルを再構築し、逆シリアル化して作業可能な形式に変換するための Python 関数や API コールの提供はユーザーの責任です。
W&B はモデルカードを使って、モデルをメモリにロードする方法の情報を文書化することを推奨しています。詳細は、Document machine learning models ページをご覧ください。
<> の中の値を自身のものに置き換えてください:
import wandb
# Run を初期化
run = wandb. init(project= "<project>" , entity= "<entity>" )
# モデルへのアクセスとダウンロード。ダウンロードしたアーティファクトへのパスを返します
downloaded_model_path = run. use_model(name= "<your-model-name>" )
モデルバージョンを以下のいずれかの形式で参照します:
latest - 最も最近リンクされたモデルバージョンを指定するために latest エイリアスを使用します。v# - 特定のバージョンを取得するために v0、v1、v2 などを使用します。alias - モデルバージョンに対してチームが設定したカスタムエイリアスを指定します。
API リファレンスガイドの use_model
例:ログされたモデルをダウンロードして使用する
例えば、以下のコードスニペットでは、ユーザーが use_model API を呼び出しています。彼らは取得したいモデルアーティファクトの名前を指定し、さらにバージョン/エイリアスも提供しています。その後、API から返されたパスを downloaded_model_path 変数に格納しています。
import wandb
entity = "luka"
project = "NLP_Experiments"
alias = "latest" # モデルバージョンのセマンティックニックネームまたは識別子
model_artifact_name = "fine-tuned-model"
# Run を初期化
run = wandb. init()
# モデルへのアクセスとダウンロード。ダウンロードしたアーティファクトへのパスを返します
downloaded_model_path = run. use_model(name= f " { entity/ project/ model_artifact_name} : { alias} " )
2024年のW&B Model Registryの廃止予定について 以下のタブでは、近日廃止予定の Model Registry を使用してモデルアーティファクトを利用する方法を示しています。
W&B Registry を使用して、モデルアーティファクトを追跡、整理、利用します。詳細は Registry docs を参照してください。
<> の中の値を自身のものに置き換えてください:
import wandb
# Run を初期化
run = wandb. init(project= "<project>" , entity= "<entity>" )
# モデルへのアクセスとダウンロード。ダウンロードしたアーティファクトへのパスを返します
downloaded_model_path = run. use_model(name= "<your-model-name>" )
モデルバージョンを以下のいずれかの形式で参照します:
latest - 最も最近リンクされたモデルバージョンを指定するために latest エイリアスを使用します。v# - 特定のバージョンを取得するために v0、v1、v2 などを使用します。alias - モデルバージョンに対してチームが設定したカスタムエイリアスを指定します。
API リファレンスガイドの use_model
https://wandb.ai/registry/model の Model Registry App に移動します。ダウンロードしたいモデルを含む登録済みモデル名の隣にある 詳細を見る を選択します。
バージョンセクション内で、ダウンロードしたいモデルバージョンの隣にある表示ボタンを選択します。
ファイル タブを選択します。ダウンロードしたいモデルファイルの隣にあるダウンロードボタンをクリックします。
9 - 機械学習モデルを文書化する
モデル カードに説明を追加して、モデルをドキュメント化する
モデルレジストリに登録されたモデルのモデルカードに説明を追加して、機械学習モデルの側面を文書化します。文書化する価値があるトピックには以下のものがあります:
Summary : モデルの概要。モデルの目的。モデルが使用する機械学習フレームワークなど。Training data : 使用したトレーニングデータについて、トレーニングデータセットで行ったプロセッシング、そのデータがどこに保存されているかなどを説明します。Architecture : モデルのアーキテクチャー、レイヤー、および特定の設計選択に関する情報。Deserialize the model : チームの誰かがモデルをメモリにロードする方法についての情報を提供します。Task : 機械学習モデルが実行するよう設計された特定のタスクや問題のタイプ。モデルの意図された能力の分類です。License : 機械学習モデルの使用に関連する法的条件と許可。モデルユーザーが法的な枠組みのもとでモデルを利用できることを理解するのに役立ちます。References : 関連する研究論文、データセット、または外部リソースへの引用や参照。Deployment : モデルがどのように、そしてどこにデプロイメントされているのか、他の企業システムにどのように統合されているかに関するガイダンスを含む詳細。
モデルカードに説明を追加する
https://wandb.ai/registry/model で W&B モデルレジストリ アプリに移動します。モデルカードを作成したい登録済みモデル名の横にある View details を選択します。
Model card セクションに移動します。
Description フィールド内に、機械学習モデルに関する情報を入力します。モデルカード内のテキストは Markdown マークアップ言語 でフォーマットします。
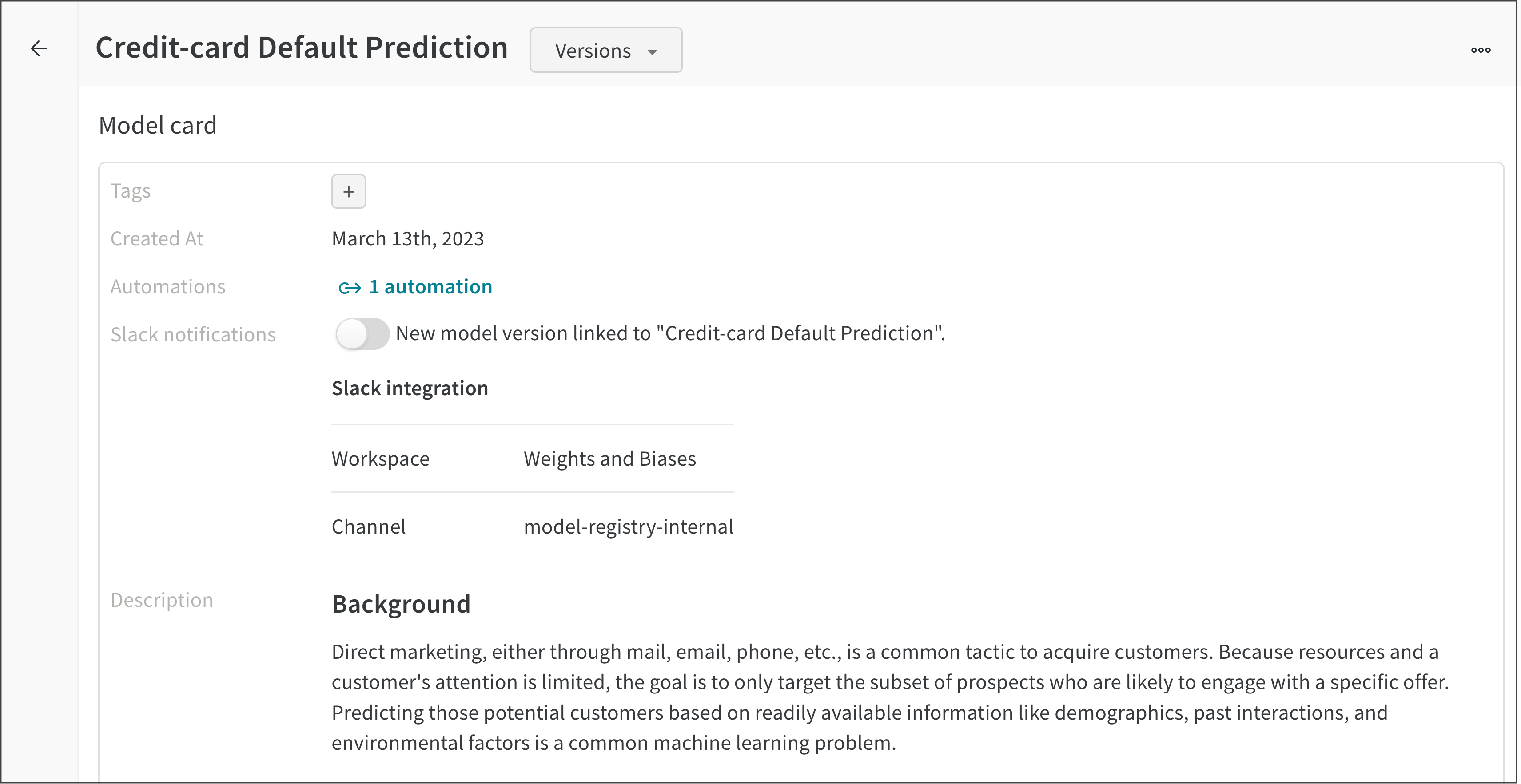
例えば、次の画像は Credit-card Default Prediction という登録済みモデルのモデルカードを示しています。
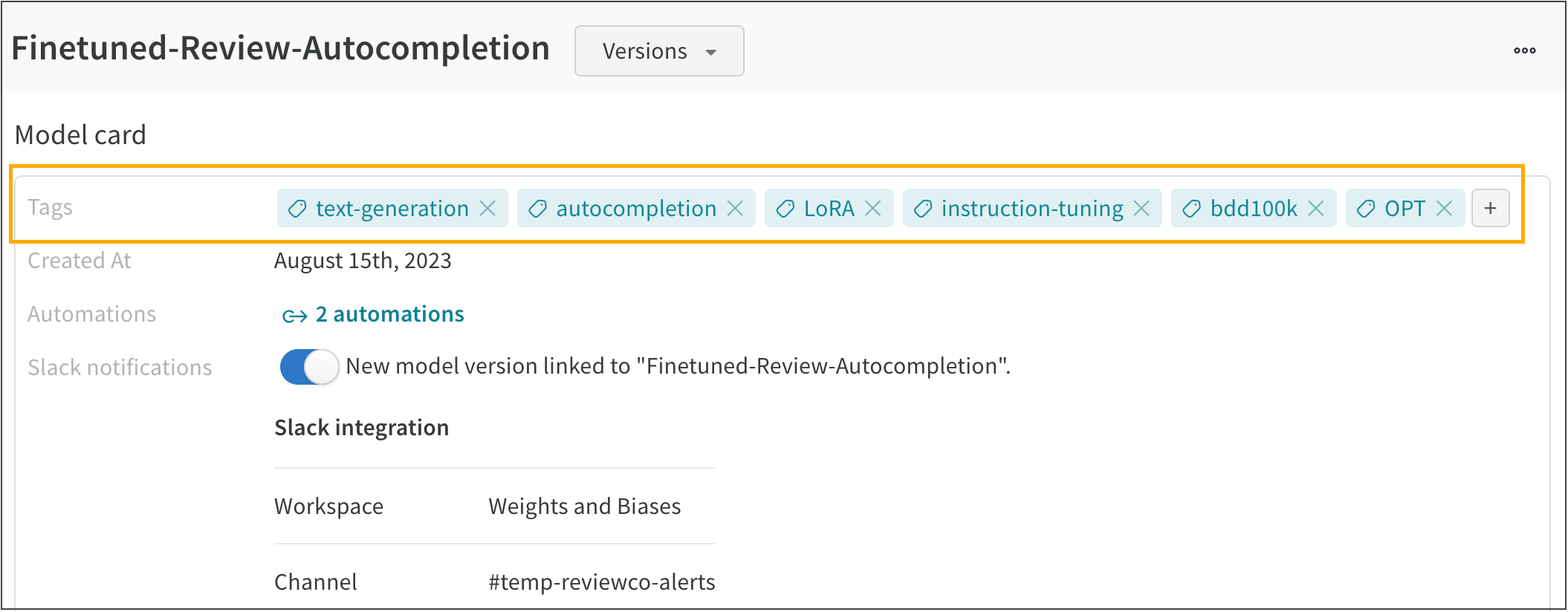
10 - アラートと通知を作成する
新しいモデルバージョンがモデルレジストリにリンクされた時に Slack 通知を受け取る。
新しいモデルバージョンがモデルレジストリにリンクされたときに、Slack 通知を受け取る。
https://wandb.ai/registry/model で W&B Model Registry アプリを開きます。通知を受け取りたい登録済みモデルを選択します。
Connect Slack ボタンをクリックします。
OAuth ページに表示される Slack ワークスペースで W&B を有効にするための指示に従います。
チームのために Slack 通知を設定すると、通知を受け取る登録済みモデルを選択できます。
チームのために Slack 通知を設定した場合、Connect Slack ボタンの代わりに New model version linked to… と書かれたトグルが表示されます。
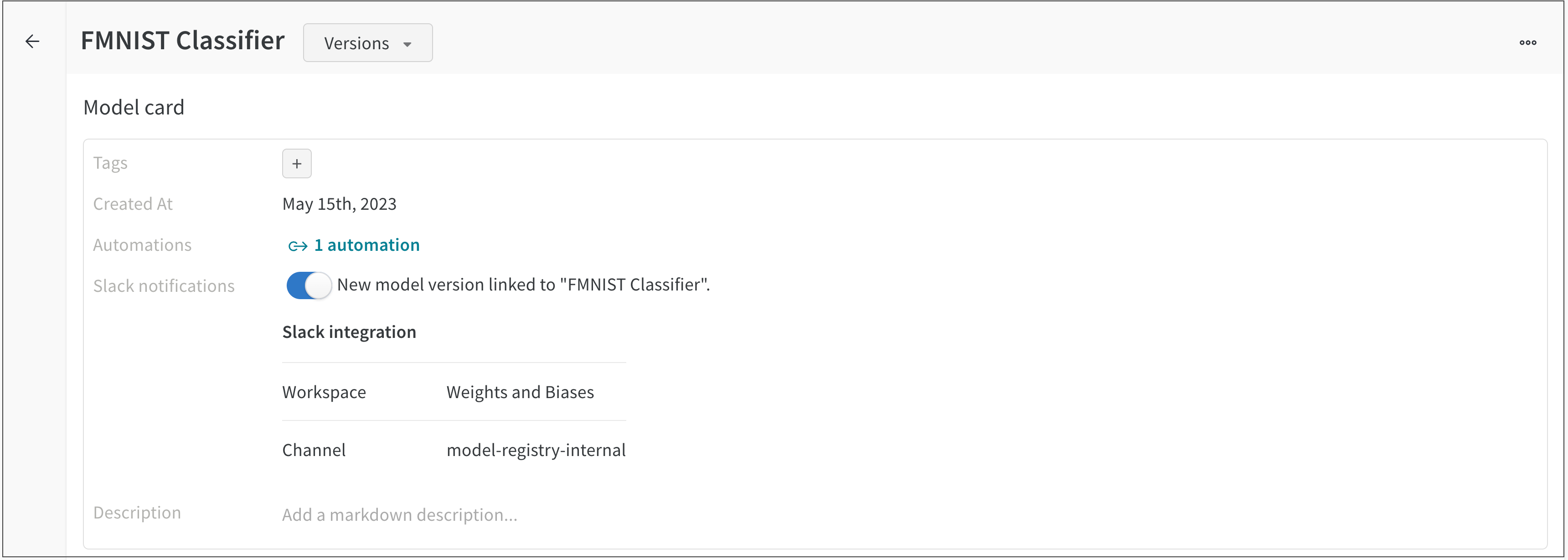
下のスクリーンショットは Slack 通知が設定された FMNIST 分類器の登録済みモデルを示しています。
新しいモデルバージョンが FMNIST 分類器の登録済みモデルにリンクされるたびに、接続された Slack チャンネルにメッセージが自動的に投稿されます。
11 - データ ガバナンスとアクセス コントロールを管理する
モデルレジストリのロールベース アクセス制御 (RBAC) を使用して、誰が保護されたエイリアスを更新できるかを制御します。
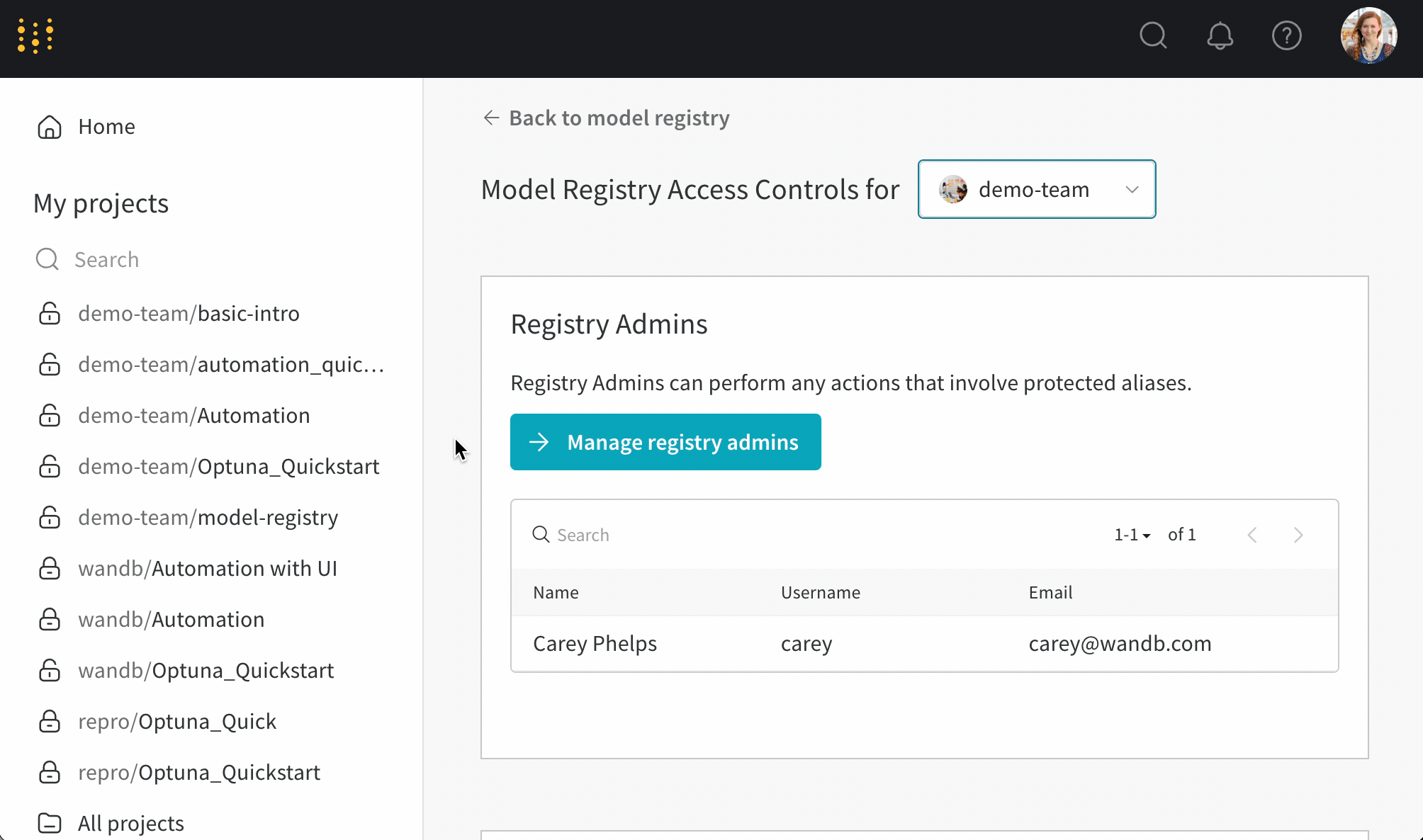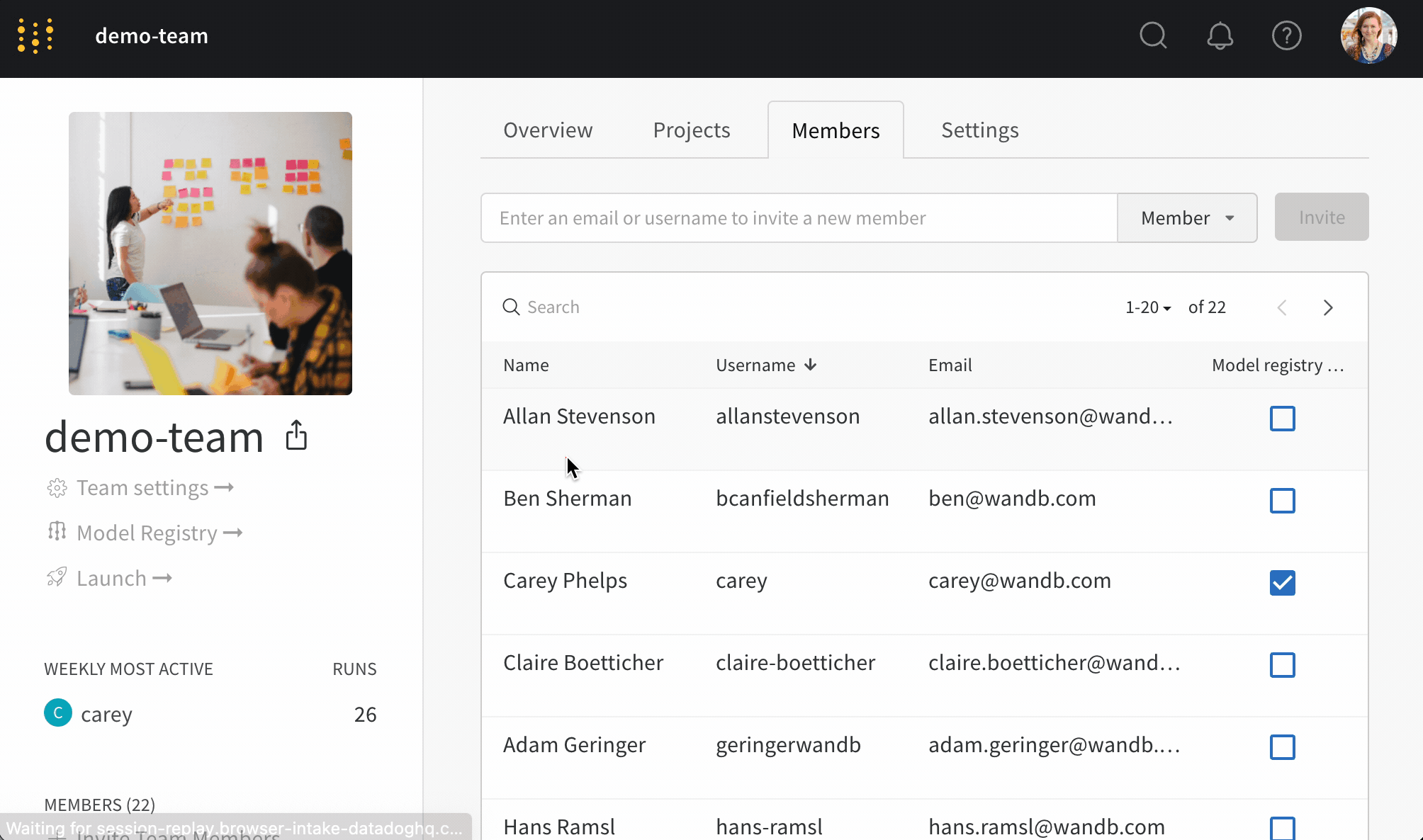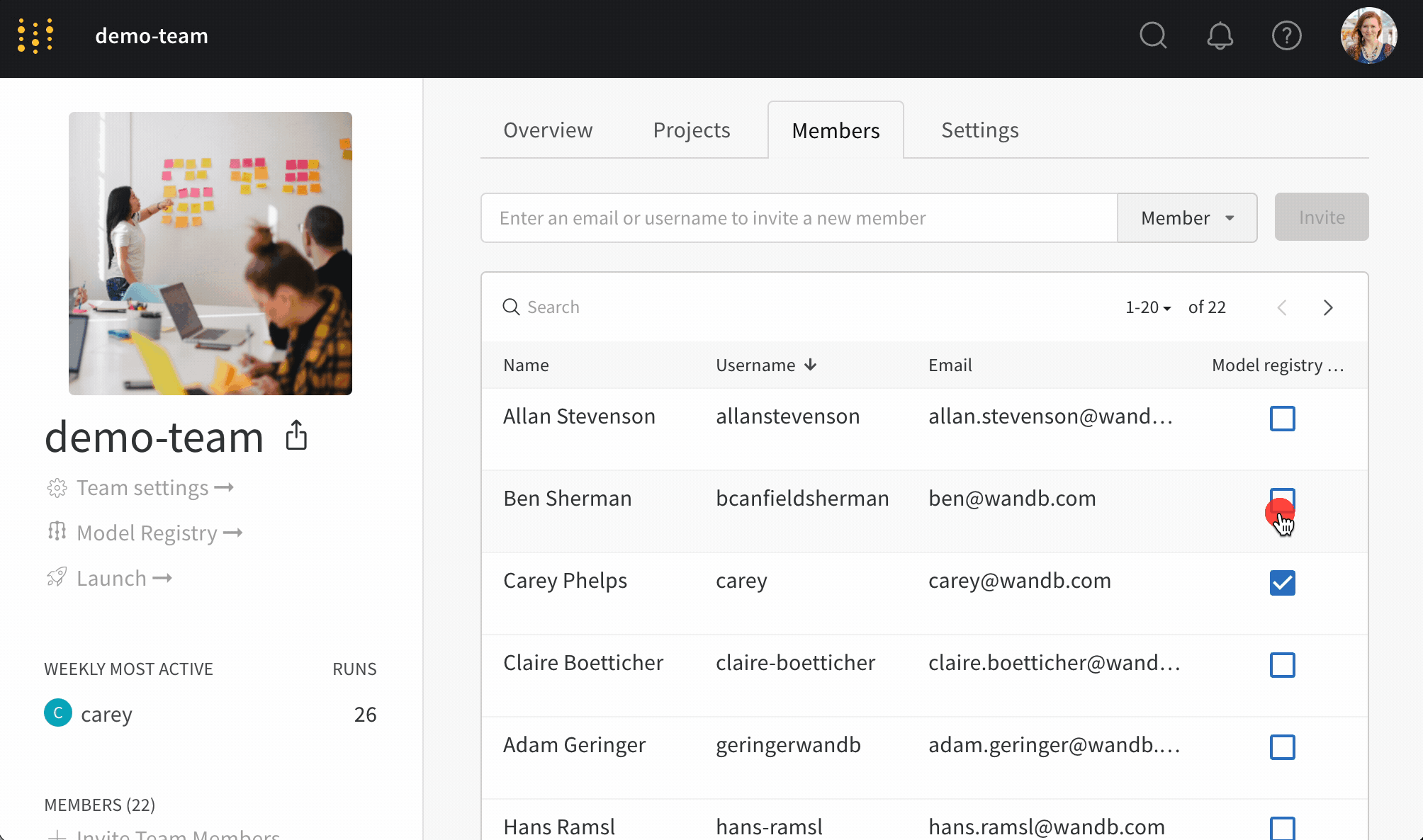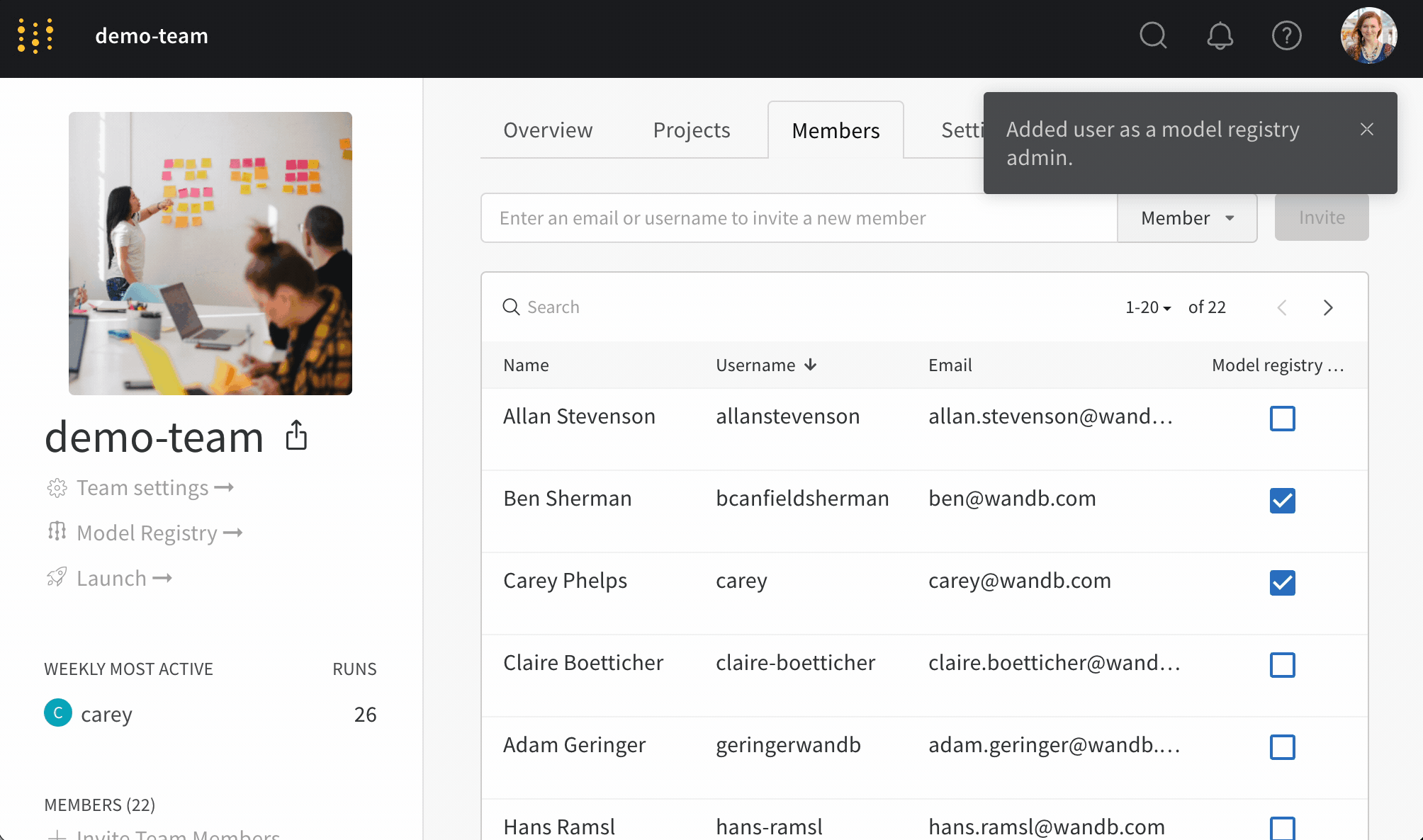
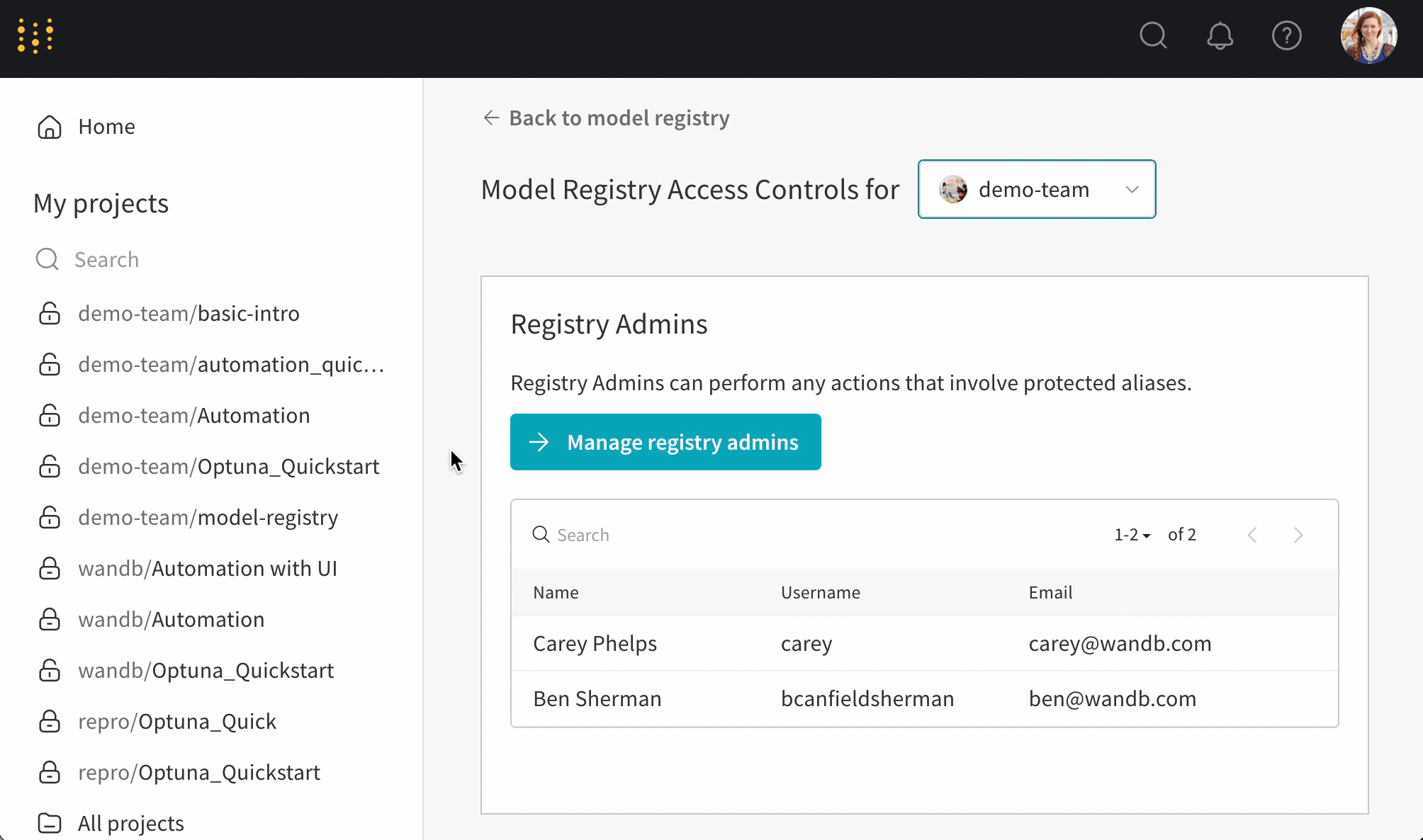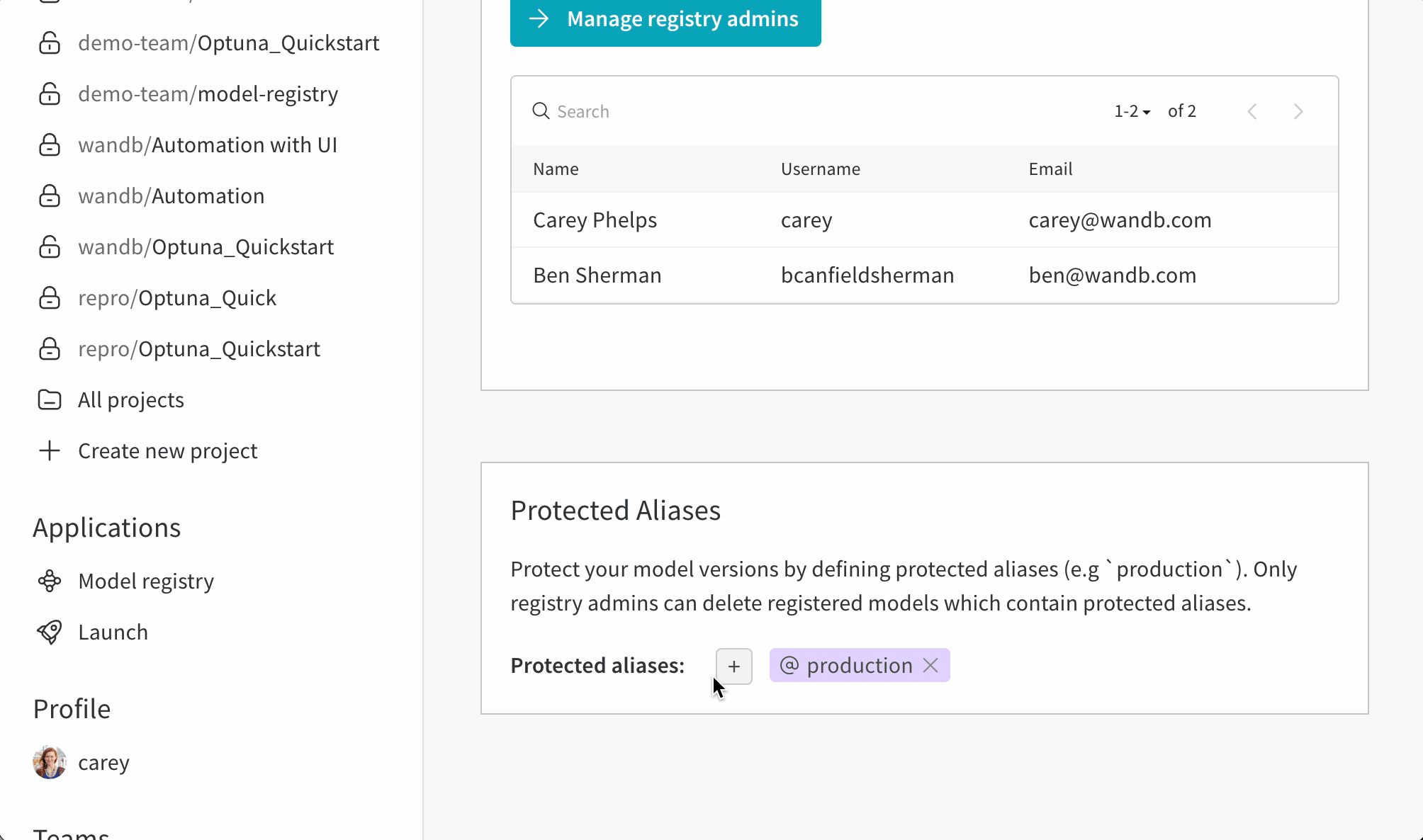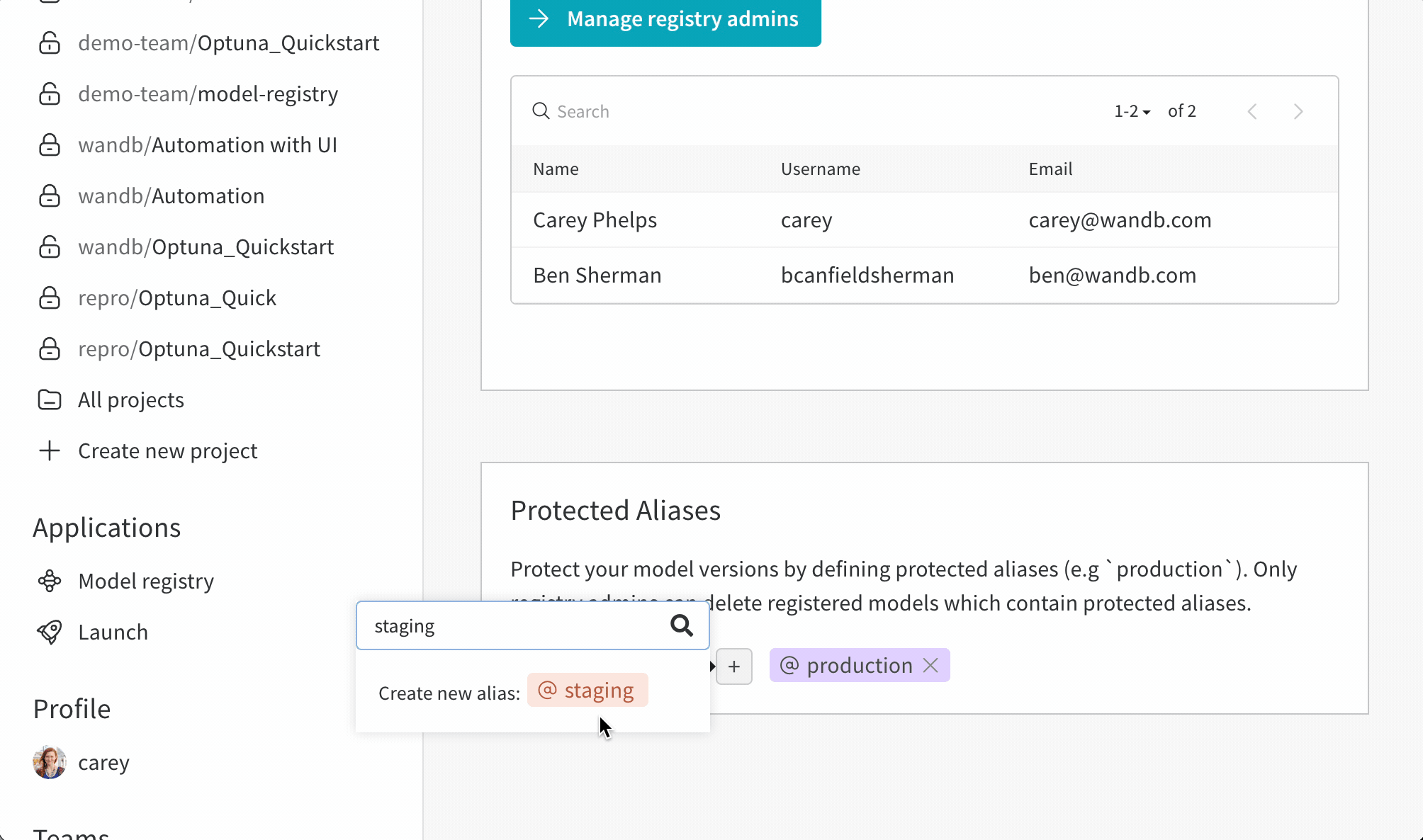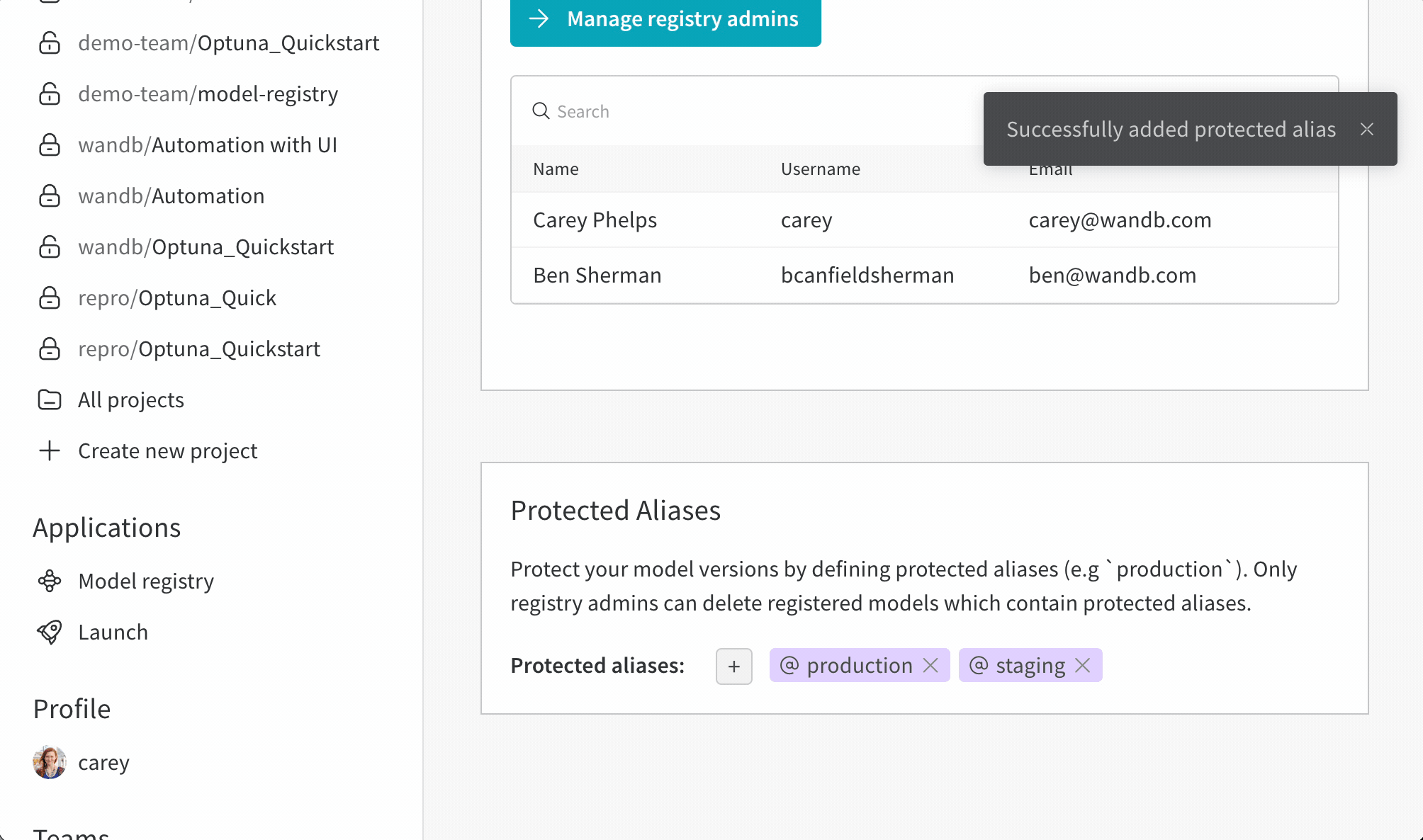
保護されたエイリアス を使用して、モデル開発パイプラインの主要なステージを表現します。モデルレジストリ管理者 のみが保護されたエイリアスを追加、変更、または削除できます。モデルレジストリ管理者は保護されたエイリアスを定義し、使用することができます。W&B は非管理ユーザーがモデルバージョンから保護されたエイリアスを追加または削除することをブロックします。
チーム管理者または現在のレジストリ管理者のみがレジストリ管理者のリストを管理できます。
例えば、staging と production を保護されたエイリアスとして設定したとします。チームのどのメンバーも新しいモデルバージョンを追加できますが、staging または production エイリアスを追加できるのは管理者のみです。
アクセス制御の設定
次の手順で、チームのモデルレジストリに対するアクセス制御を設定します。
W&B モデルレジストリアプリケーションに移動します:https://wandb.ai/registry/model
ページ右上のギアボタンを選択します。
Manage registry admins ボタンを選択します。Members タブ内で、モデルバージョンから保護されたエイリアスを追加および削除するアクセス権を付与したいユーザーを選択します。
保護されたエイリアスの追加
W&B モデルレジストリアプリケーションに移動します:https://wandb.ai/registry/model
ページ右上のギアボタンを選択します。
Protected Aliases セクションまでスクロールダウンします。プラスアイコン (+ ) をクリックして新しいエイリアスを追加します。